【Python Coding】カテゴリ変数を数値化する”Label Encoding”について解説します

こんにちは、たなです。
データ分析でカテゴリ変数の数値化は必須
データ分析や機械学習のモデル構築では「カテゴリ変数」を数値化する必要性が出てきます。本記事では、カテゴリ変数を数値化できる「Labelエンコーディング」について、欠損値なし/ありの2パターンにわけて、詳しく解説していきます。
「カテゴリ変数を数値化する方法を知りたい」
「モデルの精度をあげるための手法を知っておきたい」
という人は参考にしてみてください。
本記事の内容
- 欠損値がない場合のLabelエンコーディング処理について
- 欠損値がある場合のLabelエンコーディング処理について
僕のブログでは【完全ガイド】pythonの学習サイトをレベル別に紹介!【基礎から機械学習・人工知能までのロードマップ】という記事も公開しています。より高みを目指したい人は参考にしてみてください。
pythonの学習ロードマップへpythonでカテゴリ変数を数値化する「Labelエンコーディング」の方法を解説

欠損値がない場合のLabelエンコーディング処理
まずは「欠損値がない」場合のパターンから見ていきましょう。
必要ライブラリのインポート(共通)
import pandas as pd
from sklearn.preprocessing import LabelEncoder今回はpandasとsklearnライブラリを使うので、上記コードをインポートします。
“LabelEncoder”がメインとなりますので、前処理でも使うライブラリからインポートしておきます。pandasはデータを作成するために使っていきます。
データの準備(欠損値なし)
今回は、以下のような特に意味のないデータを作成します。
具体的には、下記イメージのような簡単なデータを用意していきますが、カテゴリ変数を含んでいる点に着目しておいてください。また、欠損値を含まないデータを作成していきます。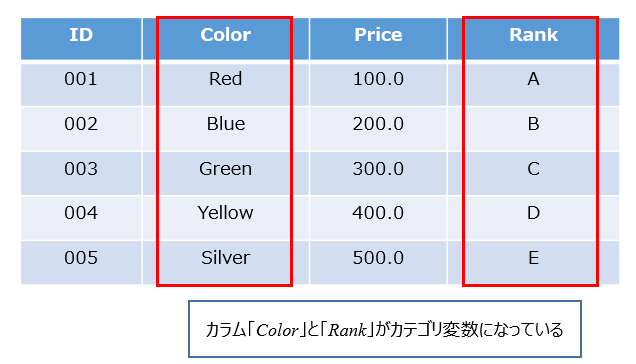
データの作成(欠損値なし)
では実際にpandasを用いて先ほどの欠損値がない簡易データを作成していきます。
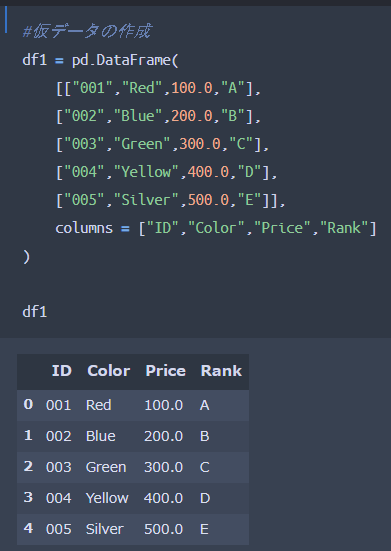
これで先ほどのデータが作成出来ました。このデータフレームに含まれているカテゴリ変数:列名「Color」と「Rank」に対して、Labelエンコーディング処理を施していくことが今回の目的になります。
Labelエンコーディングの適用
では実際に、今回のメイン処理となる「Labelエンコーディング処理」をしていきます。ここで、そもそもLabelエンコーディングとは何なのか、今一度簡単に説明しておきます。
Labelエンコーディング処理は、カテゴリ変数を数値に変換する処理のことを言います。より具体的に言うと、あるカテゴリ変数の種類が「N個」あった場合、それらのデータを「0~(N-1)」の数値に変換する処理を意味します。
例えば、先ほど作った簡易データの列名「Rank」を例に挙げてみると、ランクAからEまでの合計5種類が含まれていますよね。つまりN=5となるので、A-Eまでの文字列を0-4に変換するようなイメージとなります。ちなみに、どの文字列にどの値がラベリングされたかは重要ではないです。
Labelエンコーディング処理を施す前に、カテゴリ変数の種類がいくつあるか確認しておきます。下記コーディング結果を見てもらえばわかるように、それぞれ5個ずつ種類がありますね。
それでは、Labelエンコーディングに関連するコードを見ていきます。
Labelエンコーディング処理のポイントは以下2点です。
ポイント①:LabelEncoderを呼び出してインスタンス化しておく
ポイント②:対象となるカテゴリ変数に対して、「fit_transform()」を適用する
これを適用した結果が以下となります。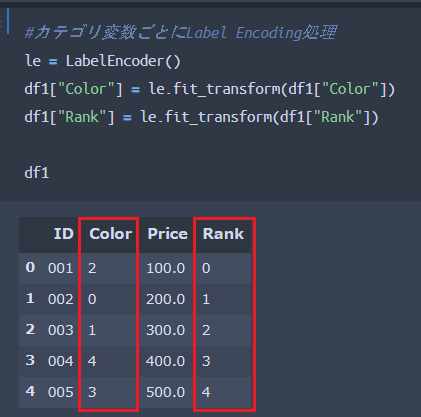
Labelエンコーディング処理をした結果、カテゴリ変数を含む列「Color」と「Rank」の値がそれぞれ0-4の値に変換されていることがわかるかと思います。
ちなみに、上記コーディングではカテゴリ変数となっている列名を指定して変換処理していますが、以下のような自作関数で汎用的に処理してもOKです。
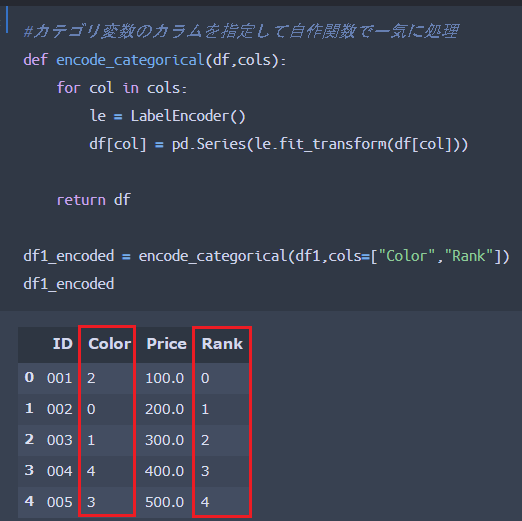
いずれも同じ結果が得られていることがわかるかと思います。
このような前処理をすることによって、モデルに対してデータを学習させていくことが可能となります。以上が欠損値がない場合のデータに対するLabelエンコーディング処理です。
欠損値がある場合のLabelエンコーディング処理
続いては欠損値がある場合のエンコーディング処理を見ていきます。
データの準備(欠損値あり)
そもそも、なぜ欠損値の有無に応じて処理をわける必要があるかと言うと、①One-hotエンコーディングの時のように、欠損値を自動で処理する機能がないこと、②欠損値を意識せずにLabelエンコーディングをすると不都合が生じることの2点が理由として挙げられます(不都合の詳細は最後に紹介しています)。
実務では様々なデータを扱う上、欠損値がないようなパーフェクトなデータに出くわすことはほぼないので、欠損値があるケースにも対処出来るようにしておくことが大切ですね。
用いるデータとしては、先ほどのデータ数を5個から100個に拡張し、「Color」と「Rank」にランダムで欠損値(None)を含んだデータを想定したいと思います。
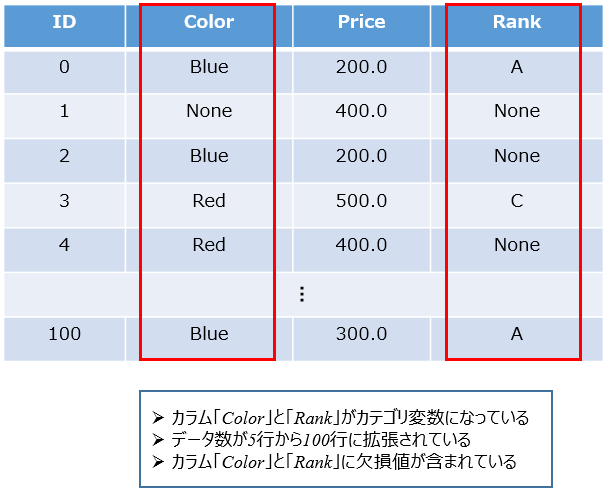
データの作成(欠損値あり)
では実際にpandasを用いて先ほどの欠損値がある簡易データを作成していきます。
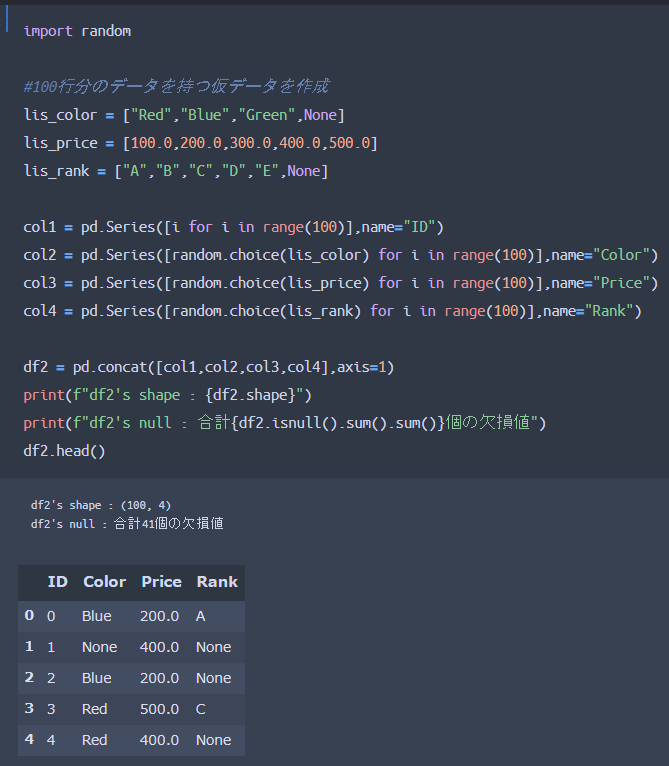
● 内容表記やランダム関数を用いて各列を作成しています
● 最終的に、pandasのconcat機能でSeries型データを結合しています
これで先ほどのデータが作成出来ましたね。欠損データも41個含んでいることがわかります。先ほどと同様に、データフレームに含まれているカテゴリ変数(列名「Color」と「Rank」)対して、Labelエンコーディング処理を施していくことが今回の目的になります。欠損値Noneが含まれている点が先ほどと異なります。
Labelエンコーディングの適用
では実際に、欠損値を含むデータに対して「Labelエンコーディング処理」をしていきましょう。Labelエンコーディング処理のポイントは先ほどと変わりませんが、pandasの「not_null()」を用いて欠損値以外のデータを指定して処理する点が重要となります。
列名「Color」に限定してコーディング結果が以下となります。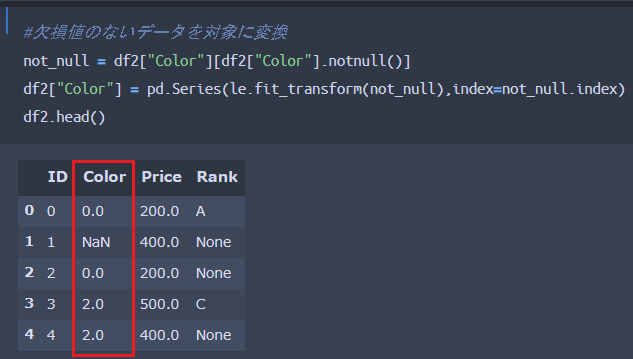
列名「Color」に対してLabelエンコーディング処理をした結果、「Color」の値が数値に変換されているとともに、欠損値はそのままになっていることがわかるかと思います。以下ではRank変数に対しても同様に処理を行っていきます。自作関数を用いてLabelエンコーディング処理を施しています。
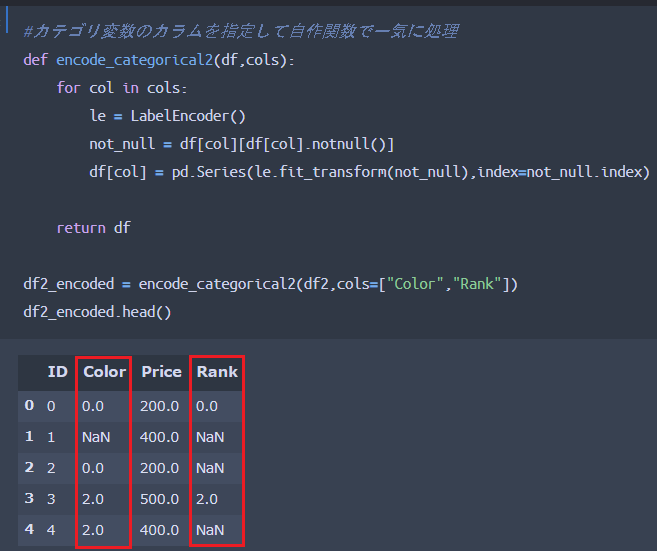
以上のように、赤枠部分が適切にLabelエンコーディング処理されているのがわかりますね。NaNはもともと欠損値となっている部分なので、そこを避けてうまく処理出来ています。
欠損値に対してLabelエンコーディングを適用した場合
ここで1つ疑問が湧くかもしれません。それは「欠損値データに対してLabelエンコーディング処理を行ったらどうなるのか?」という疑問です。
僕自身も疑問に持ったことがあったのですが、結論から言うと「欠損値は欠損のままにして、欠損値以外のデータに対してLabelエンコーディング処理をすべき」です。
なぜなら、欠損値同士が異なる値としてラベル変換されてしまうからです。
欠損値に対してもLabelエンコーディング処理を行ったコードが以下なのですが、以下赤丸部分を見てもらった方がわかりやすいかと思います。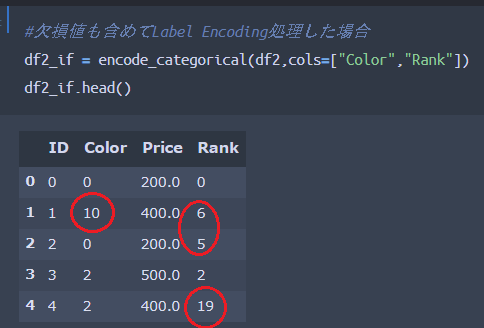
先ほどの欠損部分と比較してもらえればわかるように、欠損値も何かしらの数値に変換されているのがわかります。そして、欠損値がすべて同じ数値として変換されるわけではなく、各々異なる数値として変換されてしまっているのです。
モデルを構築する上で、「欠損」という状態が何かしら意味を持つと考える方法もありますが、各々の欠損値自体に違いはないはずですよね。同じ数値(例えば999)として変換されるならまだしも、全く別の数値として変換されてしまっている以上、モデル精度を下げかねない前処理になってしまいます。
そのため、Labelエンコーディング処理を施す場合には、欠損値の有無でわけた方が望ましいのです。
まとめ:Labelエンコーディングを使えばカテゴリ変数の数値化でモデル精度を向上させられる

今回は、カテゴリ変数の数値化処理として「Labelエンコーディング」について紹介してきました。
「カテゴリ変数の数値化」はデータ分析でもかなり重要な手法となります。pandas操作の幅も広がるので、ぜひこの機会に使えるようにしてみてください。
冒頭でも紹介しましたが、pythonの学習方法を【完全ガイド】pythonの学習サイトをレベル別に紹介!【基礎から機械学習・人工知能までのロードマップ】でまとめています。良ければあわせて読んでみてください。
【完全ガイド】pythonの学習サイトをレベル別に紹介!【基礎から機械学習・人工知能までのロードマップ】
pythonを極めたいすべての人に贈る学習ロードマップ。おすすめの学習サイトをレベル別に紹介しているので、pythonのレベルをあげていきたいと考えるすべての人に読んで欲しい記事です。これさえ読めば、自分に合っている学習方法やこれから目指すべき方向性がわかります。pythonライフ、楽しんでいきましょう。
よいpythonライフを。