
[Python] seabornを使ってカーネル密度(Density Plot)を描く方法

こんにちは、たなです。
今回はPythonのseabornを使ってカーネル密度(Density Plot)を描く方法を解説していきます。ヒストグラム同様に、1変量データを可視化することで、データの実態を明らかにできて便利です。
本記事の内容
本記事ではcsvファイルに格納したアヤメデータを使っていきます。本記事を学べば、以下が出来るようになります。
csvファイルを読み込んでデータフレーム化する方法
カーネル密度(Density Plot)を描く2つの方法
品種別にカーネル密度を描く方法
本記事のゴール
下図のようなグラフをseabornで表示できるようになります。
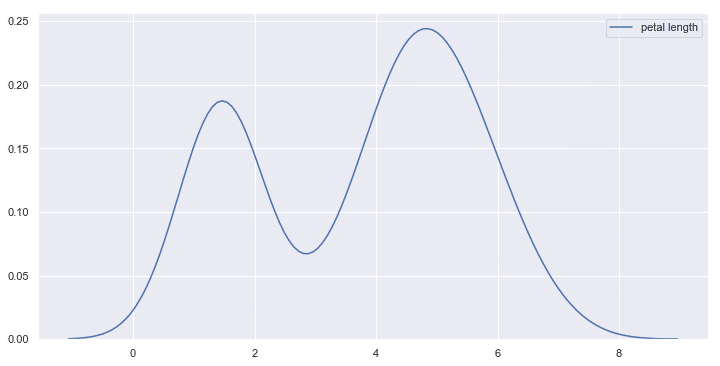
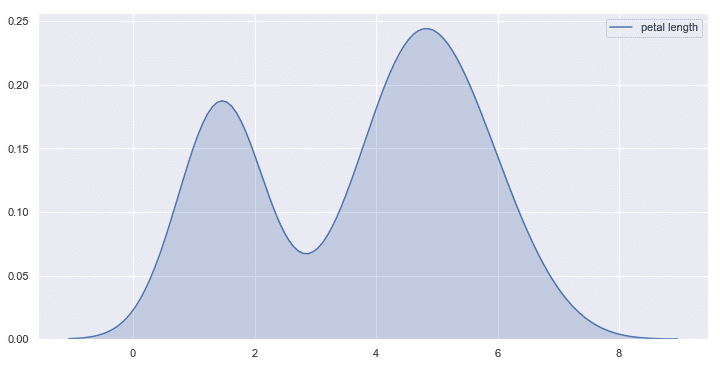
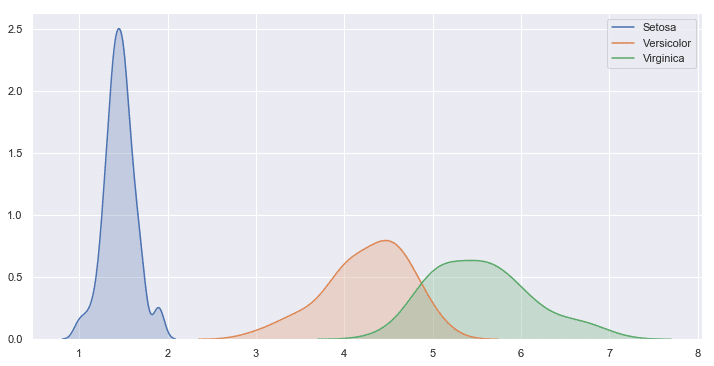
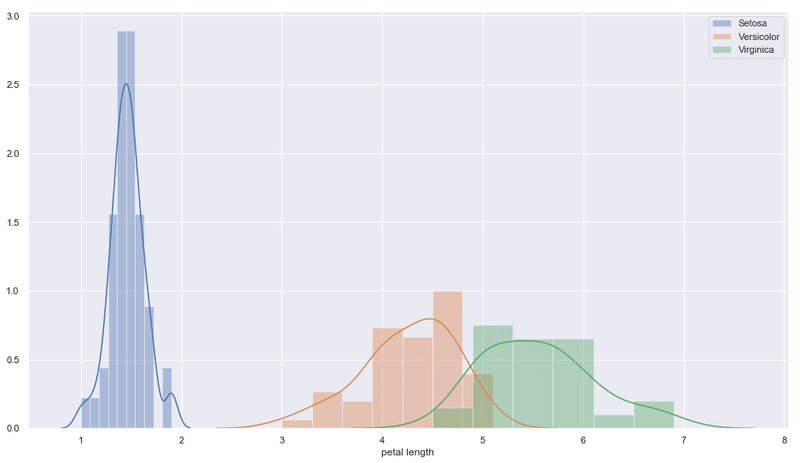
本記事のプレゼント
Googleドライブリンクで以下を配布します
①:元データ(csvファイル)
②:本記事内で使用したコード(Jupyter Notebook)
Pythonのseabornを使ってカーネル密度(Density Plot)を描く方法

必要ライブラリのインポート
まず以下のライブラリをインポートしておきます。初めて使うライブラリがある場合は、別途"pip install <パッケージ名>"でインストールしておいてください。
ここから先は
3,668字
/
7画像
¥ 300
この記事が気に入ったらサポートをしてみませんか?