【Python Coding】クラスラベルに対するマッピング処理


こんにちは、TAKです。
前回記事「カテゴリ変数を数値化する必要性」の中でクラスラベルに対するマッピングを紹介したので、今回は実際にpythonを用いて「クラスラベルに対するマッピング処理」を実装する方法を紹介していきたいと思います。
python codingなので、いつものようにJupyter Notebookベースでコードを紹介していきます。
必要に応じて、みなさんもローカル環境で実装トライしてみてくださいね。
クラスラベルに対するマッピング処理
必要ライブラリのインポート
今回はpandasだけあればOKなので、上記のようにpandasをインポートしておいてください。
pandasはデータ作成用に使います。
データの準備
今回は、冒頭の前回記事内でも紹介しているローン審査を想定した簡単なデータを利用していきます。
具体的には、下記イメージのような簡単なデータを用意した上で、最終的にクラスラベルに対するマッピング処理を施していきます。
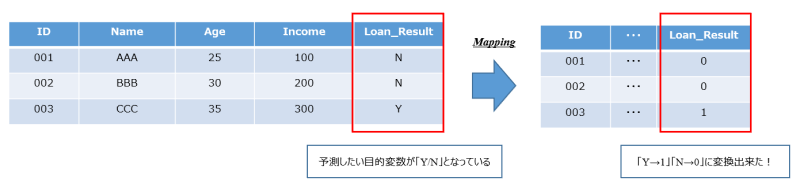
そもそも何で必要なのか?
今回利用するデータについて確認したところで、そもそもなぜ今回紹介するマッピング処理が必要となるかについて説明しておきたいと思います。
上記のローン審査を想定した場合、4つの特徴量をモデルに与えて学習させ、未知データ(例えば、Age40・Income200のデータ)を与えた時に、ローン審査通過出来るかどうかを正確に予測させることを目的としていますよね(現実的にこんなに少ない特徴量から予測することは不可能に近いですが、説明する観点から単純化しています)。
機械学習でもAIモデルを構築する場合でも、最終的に目指すべきは汎化性能の向上、もう少し分かりやすく言えば、モデルにくっついているパラメータの最適化です。このパラメータを最適化するために、学習過程のパラメータがイイ感じなのかイケてない感じなのかを確認する必要があります。その役割を果たすのが「目的関数(損失関数)」と言われるものです。
この目的関数(損失関数)では、「構築したモデルから出力される予測値」と「正解値(ラベル)」の2つを入力値とし、そこから損失値、つまりモデルパラメータのイケていない度を出力します。
つまり、正解値(ラベル)が今回のように「Y/N」となっている場合、目的関数(損失関数)にそのままの型でインプットさせるよりも、「1/0」のような数値に変換した上でインプットした方が良いということです。文字のままだと計算出来ないですからね。
モデルの仕組みについて「?」という方は、「ゼロから学ぶAI」という記事で仕組みを紹介しているのでそちらを参考にしてみてください。
https://vector-ium.com/ai-zero-learn1/
データの作成
では実際にpandasを用いて先ほどのデータを作成しましょう。

● pandasのDataFrameで新しくデータを作成出来ます

● 説明変数をX、目的変数(正解ラベル)をyとすることが一般的です
● df.iloc[:,-1]を用いることで、データフレームの[全行:最終列]を切り出しています
● 正解ラベルyが「Series型」になっている点がポイントです
クラスラベルに対するマッピング処理
では実際に、今回のメイン処理となる「クラスラベルに対するマッピング処理」をしていきます。
具体的には、先ほど説明した「Y/N」となっている正解ラベルを「1/0」に変換することが目的です。
これを実現するための処理の流れは下記2つです。
処理②:Series型のラベルyに対して、用意した辞書をマッピングする
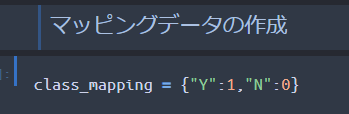
● 「Y→1」「N→0」にしたいので、これを対応付けた辞書を用意します
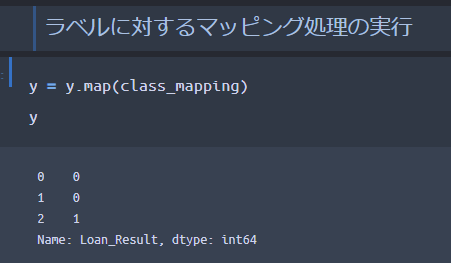
● 「y(Series型).map(用意した辞書)」としてあげることで、「Y→1」「N→0」に変換出来ます
● 最終的に、正解ラベルのyが適切に変換されていることがわかりますね
まとめ
いかがだったでしょうか?
以上がクラスラベルに対するマッピング処理の紹介となります。
処理自体は大して難しくないので、どのような時に使える方法なのか、なぜマッピング処理をする必要があるのかといった趣旨もしっかりと理解した上で使いこなしてみてください。
では今回はこのへんで。