カテゴリ変数を数値化する必要性とオススメ手法を紹介します


こんにちは、TAKです。
前回の記事で変数の種類(量的変数とカテゴリ変数)について紹介しました。
今回は、データ分析においては必須の処理である「カテゴリ変数を数値化する必要性とオススメ手法」について紹介していきます。
データサイエンスの勉強を始めたばかりの方は、「そもそも何でカテゴリ変数を数値化する必要があるのか?」「数値化する手法って色々あるっぽいけど、結局何を使えばいいのか?」といった疑問をお持ちかと思いますので、こういった疑問を解決することを目的としています。
1. データサイエンスの勉強を始めたばかりの方
2. 前処理として「カテゴリ変数を数値化する方法」を知りたい方
なお、この記事では全体像を理解することを目的にしているため、pythonを用いたコーディングを知りたい方は、サブタイトル内にあるリンク先から確認してみてください。
カテゴリ変数を数値化する「必要性」

まず最初に、カテゴリ変数を数値化する必要性について解説していきます。
「あえて説明しなくても知ってるよ!」という方も多いと思いますので、簡単な説明に留めておきます。
結論から言ってしまえば、モデルは数値以外のデータを理解出来ないからです。
数値以外のデータ、つまりカテゴリ変数は僕ら人間が見れば当然理解出来る内容ですが、機械は定量的に表現されたデータしか理解出来ませんよね。そのため、機械学習やデータサイエンスで構築したモデルに大量のデータを学習させる「前段階」として、カテゴリ変数を「何かしらの方法」で数値化しておく必要があるということです。
この「前段階」のことを一般的に「前処理」と呼びます。データ分析するにあたって、分析の妨げになるような「いけてないデータ」が含まれていたならば、モデル構築したりパラメータを最適化させる前に、「まずデータをキレイにしようよ」っていうフェーズだと理解してもらえれば十分です。
以下ではカテゴリ変数を数値化するための「何かしらの方法」について解説していきます。
カテゴリ変数を数値化する「方法」
方法①:One-hotエンコーディング
では実際にカテゴリ変数を数値化するための手法を紹介していきます。
書籍などを見ると複数の種類があり、場合によって使い分けている人もいるようです。
ただ僕のブログでは「非エンジニア」の方向けに、シンプルな使える方法を紹介しているので、実務的にも使える手法のみを取り上げたいと思います。
まず一つ目の方法は「One-hot エンコーディング処理」という方法です。
これは絶対に知っておいて損はない方法だと思うので、まずは概要を理解して、その後リンク先からpythonでの実装コードまで抑えるようにしてみてください。
ここで簡単な具体例をみてみましょう。
現実にはあり得ないですが、Color変数からPriceを予測するモデルを作るためのシンプルなデータを想定します(IDのような連番管理データは、モデル構築の観点から除外されるのが一般的です)。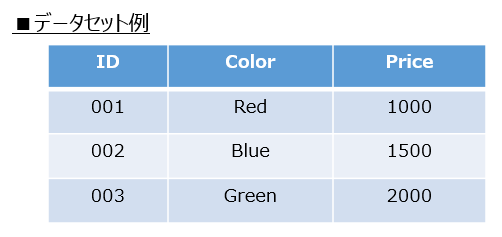
このとき、カテゴリ変数であるColor変数を数値化する必要がありますよね。
なぜなら、モデルに「Red,Blue,Green」のような情報をそのまま理解させることが出来ないからです。
「Red→1」「Blue→2」「Green→3」のようにする手法も存在しますが、今回紹介するOne-hotエンコーディング処理は変数ごとのフラグ立てをするイメージとなります。
先ほどのデータセット例にOne-hotエンコーディング処理を施した結果が以下となります。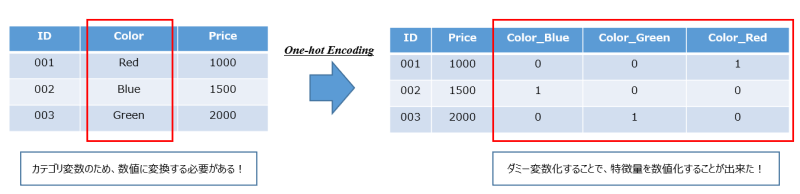
「ダミー変数化」ともいいますが、Color変数に含まれていた各要素を新たな列(特徴量)として加え、該当する場合は「1」、該当しない場合には「0」をフラグのように立てています。
こうすることで、モデルにColor変数が持つ意味を理解させることが出来るので、カテゴリ変数を数値化させる方法としてはよく使われます。ただ、One-hotエンコーディング処理を施すことで、特徴量である列が横長に増えるため、場合によっては特徴量選択や次元圧縮のような方法をしてあげる必要があります。留意点として頭の片隅に入れておいてください。
具体的なpythonを用いたコーディング方法は以下の記事を参考にしてください。
方法②:マッピング処理
カテゴリ変数を数値化する手法としては、先ほどの「One-hot エンコーディング」を知っていれば十分なのですが、場合によっては使えるもう一つの方法を紹介しておきます。
それは、クラスラベルに対してマッピングする方法です。
イメージしやすいように、こちらも現実にはあり得ないですが、簡単な個人情報からローン審査可否を予測するモデルを作るためのシンプルなデータを想定してみます。
ここでは、Age変数やIncome変数といった数値データをモデルに学習させて、最終的にLoan_Resultを予測したいと仮定します。先ほどは説明変数がカテゴリ変数だったケースですが、今回は目的変数がカテゴリ変数のケースである点が異なります。

このようなデータセットの場合、目的変数をそのまま「Y/N」で扱ってもよいですが、「1/0」のように変換してあげることが一般的です。先ほどのようなOne-hot エンコーディング処理を施してしまうと、「Yの列」「Nの列」が出来てしまうため、別の方法をしてあげる必要があります。
このデータセットにマッピング処理を施した結果が以下になります。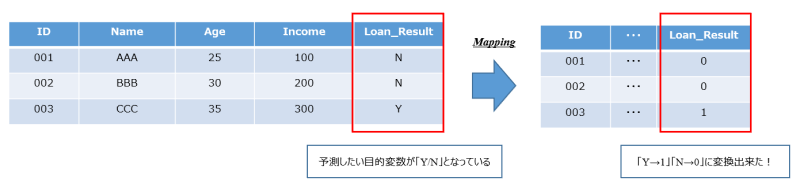
このようにデータを学習する前段階として数値に変換することで、より良いモデルを構築することが出来ます(先ほどのOne-hotエンコーディング処理に比べれば「前処理」というニュアンスは低いですが)。
具体的なpythonを用いたコーディング方法は以下の記事を参考にしてください。
方法③:Labelエンコーディング
「One-hotエンコーディングを知っておけば十分」と言っておきながら、もう一つ紹介させてください。それは、説明変数にカテゴリ変数が含まれていた場合に数値化する方法である「Labelエンコーディング」というものです。
One-hotエンコーディングは非常に便利なのですが、場合よっては特徴量が増大になり過ぎて、「多重共線性」という問題が起こり、結果的に予測精度の低いモデルとなってしまうデメリットも持ち合わせています。
そういった時に別の方法を知っておくことも重要だと思うので、Labelエンコーディングについても紹介しておきます。この方法は、カテゴリ変数の種類が「N個」ある場合に、その値を「0~(N-1)」の数値に変換する方法をいいます。
詳細は以下のpythonコーディングの記事でも紹介していますが、以下図のようなイメージです。
カテゴリ変数を数値に変換する方法の一つであることがわかるかと思います。

具体的なpythonを用いたコーディング方法は以下の記事を参考にしてください。
まとめ
いかがだったでしょうか?
今回は「前処理」の中でも重要なプロセスである「カテゴリ変数の数値化」について紹介してきました。
適切に前処理を行うことが出来たかどうかでモデル精度が大きく変わるとも言われているので、手法の概要と実際のpythonコーディングもあわせて理解してみてください。
では今回はこのへんで。