【Python Coding】Numpyの計算処理スピードを検証


こんにちは、TAKです。
前回記事で、pythonライブラリ「PandasとNumpyの違い」について書きました。
その中で、「Numpyはpython標準ライブラリよりも計算処理スピードが速い」と紹介したので、今回は実際にどのくらい計算スピードがあるのか検証してみたいと思います。
具体的には、下記2つの処理を比較し、Numpyの計算処理スピードを確認していきます。
1) python標準のlistで作成した場合
2) numpyを用いて配列を作成した場合
1) python標準のmax関数を用いた場合
2) numpyのmax関数を用いた場合
【処理その1】リスト(配列)の処理時間の比較
必要ライブラリのインポート(共通)
まずは必要なライブラリをインポートしておきましょう。

timeは時間を計測するために必要なので、numpyと合わせてインポートしておきます。
python標準機能を用いた場合
pythonの標準機能を用いて1億ケタのリストを作成してみます。
1億ケタのリストを内包表記で作成し、それに要する処理時間を示したコードが下記になります。
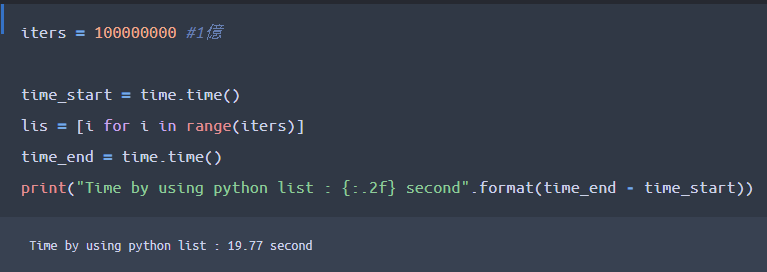
time.time()で時間測定が出来るので、間に処理をはさむことで当該処理の時間計測が出来ます。
結果、約19.77秒ほどの時間がかかったことがわかりますね。
Numpyを用いた場合
次に、Numpyを使った場合の処理をみていきましょう。
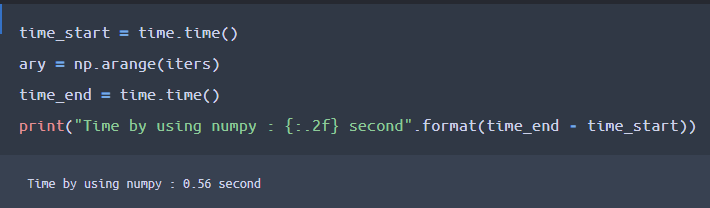
先ほどのlis変数をary変数に変えて、numpyのarange関数を用いている点が相違点です。
同じようにサンドイッチで挟んでいる処理に要する時間を測定しています。
結果、約0.56秒とかなり速い時間で1億ケタのリスト(配列)を作成したことがわかりますね。
結論
上記からわかるように、Numpyを使った方が圧倒的に速いことがわかります。
【処理その2】要約統計量の算出時間の比較
python標準機能を用いた場合
では次に、先ほど作成したリスト(配列)の最大値を算出してみたいと思います。
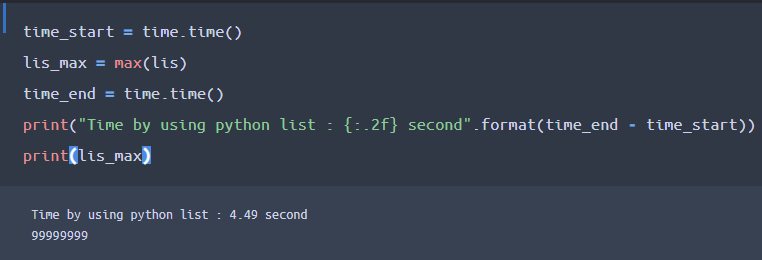
pythonの標準機能にmax関数があるので、これを使えば簡単に算出できますね。
結果、約4.49秒の時間がかかりました。
Numpyを用いた場合
では次にNumpyを使った場合をみていきましょう。
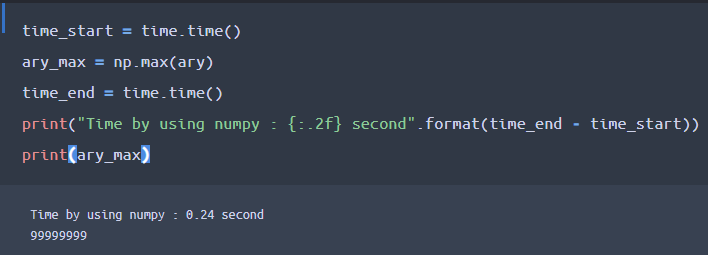
先ほどのlis_max変数をary_max変数に変えて、numpyのmax関数を用いている点が相違点です。
結果、約0.24秒とかなり速い時間で1億ケタのリスト(配列)から最大値を算出できていますね。
結論
こちらもNumpyの方が圧倒的に速い時間で処理を実現出来ていることがわかります。
まとめ
今回はNumpyがpython標準機能に比べて、処理スピードが速いことを検証してみました。
すべてNumpyを使えばいいというわけではありませんが、AIモデルを構築する場合に代表されるように、並列計算やビッグデータ処理を実現するにはNumpyを利用する方が適していると言えそうですね。
今回のCodingを通じてNumpyの処理速度が速い点を理解し、Numpyの学習に是非活かしてください。
では今回はこのへんで。