【Python Coding】pandasでデータフレームのユニーク値を抽出する方法を解説

こんにちは、たなです。
今回はpythonのpandasを用いて、データフレームを構成する要素のユニーク値を抽出する方法を紹介していきたいと思います。
ユニーク値は”重複しない値”のこと
「ユニーク値」というのは、簡単に言うと「重複しない(一意の)値」のことです。
「データフレームの構成要素を重複なしでカウントしたい!」といった場合に使える方法なので、興味のある方は参考にしてみてください。
今一つイメージが湧かないという方でも、記事内で具体例を使って説明しているので、読み進めるうちに具体的な意味や使い方がわかるようになるかと思います。
本記事の内容
- ユニーク値について
- pandasでユニーク値を取り出す”3つ”の方法を使いこなす
僕のブログでは【完全ガイド】pythonの学習サイトをレベル別に紹介!【基礎から機械学習・人工知能までのロードマップ】という記事も公開しています。より高みを目指したい人は参考にしてみてください。
pythonの学習ロードマップへpandasを使ってデータフレームの”ユニーク値”を抽出する「3つ」の方法

ユニーク値の具体例
冒頭でも軽く紹介しましたが、ユニーク値とは「一意の重複しない値」を意味します。
もう少しイメージしやすいように具体例をあげてみます。
このあとpythonコードを使った具体例でも紹介しますが、例えば「ある日に買い物をしてくれた顧客数」をカウントしたいとしましょう。ある商品を買ってくれたお客さんを調べたところ、「午前中にAさんとBさん、午後にAさんとCさん」が買い物をしていたことがわかりました。
このとき、買い物をしてくれた顧客数のユニーク値は「3人」となります。
観測データとしては「4」になりますが、午前午後と買い物をしているAさんを重複してカウントしているので、純粋な顧客数を知りたいような場合に、今回紹介する「ユニーク値」が役に立つイメージです。
必要ライブラリのインポート
import pandas as pdまず最初に、今回使うpandasをインポートしておきます。
「ユニーク値」をデータフレームの要素から抽出するにあたって、それ以外のライブラリは特に使いません。
ユニーク値の使い方【3選】
これから、2つの具体例を想定してデータフレームを構成する要素のユニーク値を抽出する方法を「3つ」紹介していきます。最初に、その「3つの方法の概要」を紹介しておきます。
- 要素とカウント結果の組み合わせを取得:df[column名].value_counts()
- 要素をnumpy配列(ndarray)形式で取得:df[column名].unique()
- 要素のカウント数を取得:df[column名].nunique()
言葉だけみても意味の違いはわかりにくいと思うので、この後具体的な違いをコードを通じて説明していきます。ここでは、いずれの方法もデータフレーム自体に適用しているのではなく、シリーズに対して適用している点がポイントです。
「DataFrameとSeriesの違いが今一つわからない」といった方は、【Python Coding】pandasでSeriesを作成する方法の記事を参考にしてみてください。
【Python Coding】pandasでSeriesを作成する方法
こんにちは、TAKです。今回は、pythonのpandasを用いて「Series型」のデータを作成する方法を紹介していきたいと思います。 僕がpythonを勉強し始めた頃は「DataFrameとSeriesの違いって何?」「Seriesを知…
具体例①:タイタニックデータ
では実際に具体例をみていきたいと思います。
まず最初に、タイタニックデータを用いて3つの使い方を比べていきます。
先ほど、データフレーム自体に対して適用するのではなく、シリーズに対して適用するとお伝えしましたが、今回はカラム「Survived」に着目していきます。これは生存者に関するラベル(目的変数)であり、「1」が助かった人、「0」が助からなかった人を意味しています。
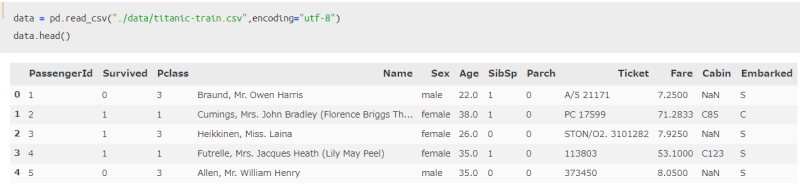
では実際に、先ほど紹介した3つの方法を適用した結果を比べてみます。
方法①:value counts()を使った場合
この方法を使った場合、Survivedの構成要素「0/1」ごとのカウント数(出現回数)の組み合わせを取得することが出来ます。こんなイメージ。

方法②:unique()を使った場合
この方法を使った場合、Survivedの構成要素「0/1」をnumpy配列(ndarray形式)で取得出来ます。以下のようなイメージ。
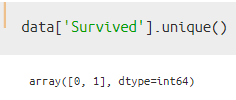
方法③:nunique()を使った場合
この方法を使った場合、Survivedの構成要素「0/1」をカウントした結果を取得出来ます。
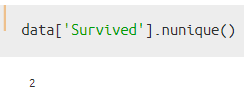
以上のように、それぞれの方法を適用した結果がだいぶ違うことがわかりますね。自分が知りたい情報や目的に応じて使い分けるようにしてみてください。
ちなみに、今回のタイタニックデータの場合には「方法①」が一番使えるかなと思います。機械学習において、ラベルの数と出現回数を確認することで、不均衡データへの対応を検討する場合に使えるためです。
具体例②:顧客購買データ
続いては、「日付とユーザー名」から構成されるシンプルなデータを作った上で、3つの方法を比較してみてようと思います。
今回使うデータと、データ集計イメージを図示したものが以下です。
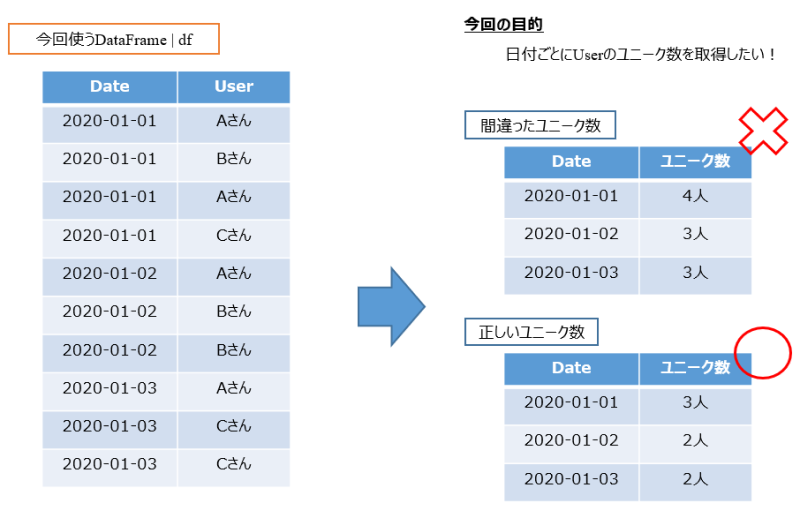
各日付ごとのユニークな顧客数を集計することを目的とした場合、「3つの方法を適用するとどうなるのか?」「3つのうちどの方法が使えるか」を確認していきます。
まず最初に、データを作っておきます。
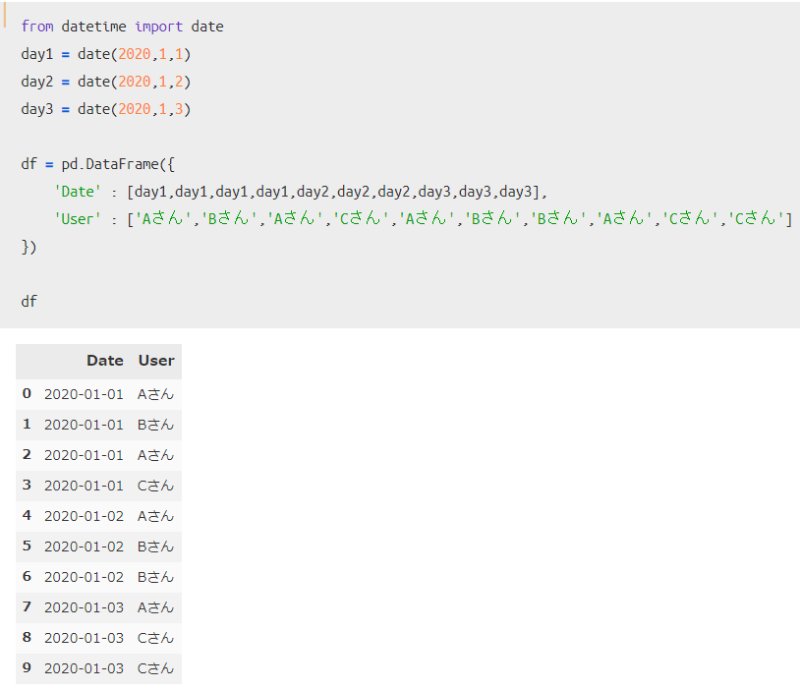
このデータフレームを前提として、3つの方法を適用した結果が以下となります。
日付ごとにまとめる必要があるため、先にgroupbyを適用し、その後ユニーク抽出をしています。
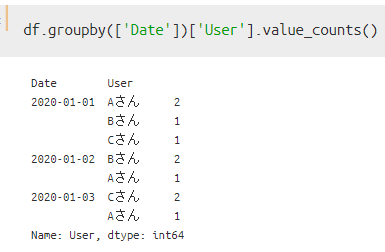
方法①:value counts()を使った場合
この場合、以下のようにUserの構成要素「Aさん/Bさん/Cさん」ごとのカウント結果(買い物回数)を取得出来ます。内訳を知れるという意味ではわかりやすいですが、今回の目的にあった結果にはなっていませんね。
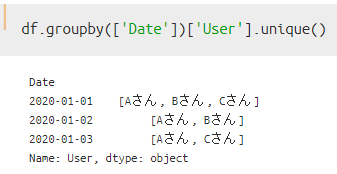
方法②:unique()を使った場合
uniqueを使うとnumpy配列でデータを取得出来ましたね。結果、Userの構成要素「Aさん/Bさん/Cさん」を取得できるので名前の把握する程度には使えますが、こちらも目的にあった結果にはなっていません。
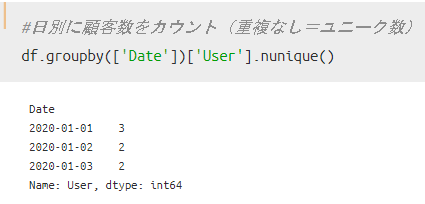
方法③:nunique()を使った場合
nuniqueを使うと、Userの構成要素「Aさん/Bさん/Cさん」ごとの買い物回数をユニーク値で取得出来ます。日付別にユニークな顧客数を取得できているので、この方法が一番目的にあっていると言えますね。
以上のように、タイタニックデータの場合とは異なり、今回の顧客購買データを想定した場合には、「方法③」が一番使いやすいことがわかりました。
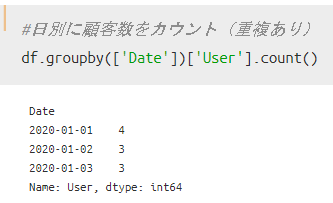
ちなみに、カウントする方法である「count」を用いた場合は、以下のように「間違ったユニーク数」を取得してしまうので、注意が必要となります。(重複を許すカウントをしたい場合には、この方法を使えばOKです。)
まとめ:pandasを使えばデータフレームからユニーク値の抽出が可能!目的に応じて使い分けよう

今回は、pythonのpandasを用いてデータフレームを構成する要素の「ユニーク値」を抽出する方法を紹介してきました。
目的に応じて使うべき方法は異なってきます。データ分析の幅も広がるはずなので、今回紹介した「3つ」の方法、ぜひ使いこなしてみてください。
冒頭でも紹介しましたが、pythonの学習方法を【完全ガイド】pythonの学習サイトをレベル別に紹介!【基礎から機械学習・人工知能までのロードマップ】でまとめています。良ければあわせて読んでみてください。
【完全ガイド】pythonの学習サイトをレベル別に紹介!【基礎から機械学習・人工知能までのロードマップ】
pythonを極めたいすべての人に贈る学習ロードマップ。おすすめの学習サイトをレベル別に紹介しているので、pythonのレベルをあげていきたいと考えるすべての人に読んで欲しい記事です。これさえ読めば、自分に合っている学習方法やこれから目指すべき方向性がわかります。pythonライフ、楽しんでいきましょう。
すてきなpythonライフを。