【Python Coding】pandasを使って数値型データを抽出&圧縮


こんにちは、TAKです。
今回はpythonのpandasを用いて、「数値型データ」を操作する方法を解説していきます。
具体的には、以下3つの方法を順に紹介していきたいと思います。
① データフレームの「データ型」を確認する方法
② 「特定のデータ型」を抽出する方法
③ 「数値型データ」を圧縮する方法
【こんな人に読んで欲しい記事です】
● pandasでデータフレーム化した後、「データ型」を確認出来るようになりたい方
● データフレームから「数値型」データのカラム(列)を抽出出来るようになりたい方
● データサイズを小さくするため、「int64型」や「float64型」を圧縮したい方
【pandas】データフレームの「データ型」を確認する方法

必要ライブラリのインポート(共通)

今回はpandasだけあれば十分なので、インポートしておきます。
ファイルの読込やデータ型の確認・変換方法などに用いていきます。
CSVファイルの読込(共通)
手元にあるcsvファイルを適当に選んでファイル読込を実行してみてください。
僕はKaggleコンペで持っていたデータサイズの大きいcsvファイルを使います。

カラムごとのデータ型を確認する
読み込んだファイルを使って、データ型を確認していきましょう。
確認する方法や好みは色々あるでしょうが、ここでは2つ簡単に紹介します。
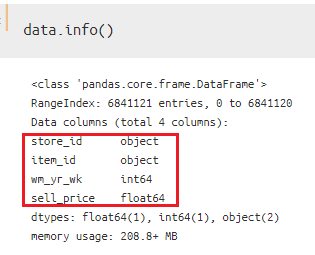
一つ目は、`df.into()`を用いて読み込んだデータフレーム全体の雰囲気をつかむ方法です。
二つ目は、`df.dtypes`を用いて、カラムごとのデータ型だけを確認する方法です。
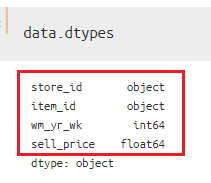
今回扱っているデータフレームは4つの特徴量(カラム)を持っていて、そのうち2つが「int64」「float64」になっていることがわかりますね。今回はデータ容量の削減も視野に入れているので、この2つのカラムを中心に扱っていくことにします。
【pandas】データフレームから「数値型」の列を抽出する方法

データ型を変換する前に、一つ使える方法を紹介しておきましょう。
それは、特定のデータ型を抽出する方法です。
今回のデータフレームに限った話ではありませんが、どんなデータでも色んな特徴量(カラム)を持っていて、そのデータ型がすべて一緒ということは通常ありえないですよね。今回のように、特定のデータ型を対象に処理をしたいようなニーズもあるので、紹介しておきます。
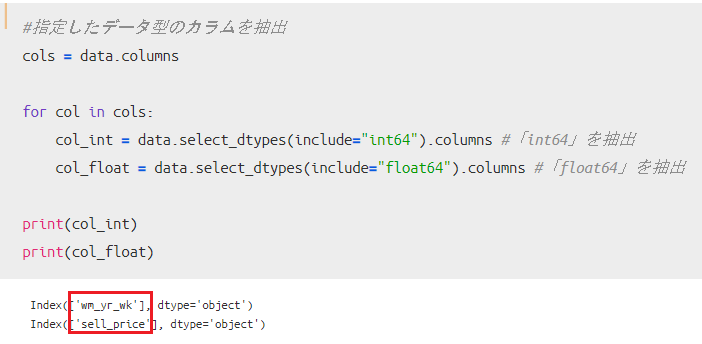
特定のデータ型を指定する方法は`df.select_dtypes()`になります。
引数includeにデータ型を指定してあれば、対象となるカラムの抽出が可能です。
今回は、「数値型データ」である「int型」と「float型」のカラムを抽出しています。
この方法を使いつつ、次からデータ型の変換作業をしていきます。
【pandas】数値型データ(int64/float64)を圧縮する方法

「int64」と「float64」を変換する
では実際に、「int64」と「float64」を対象にデータサイズを圧縮していきます。
と、その前に重要なポイントが一つ。
それは、「int64」や「float64」は「容量の大きいデータ型」であり、データを読み込んだ時はデフォルトでどのようなデータでも読み込めるように「int64」「float64」になっているということです。

つまり、「int64」や「float64」が含まれている場合、データ容量を小さくする余地があるということです。今回僕が扱っているような膨大なcsvファイルに出くわした時には、容量の削減が必須になるので覚えておきましょう。
具体的にデータ型を変換する方法としては、`pd.to_numeric()`を使います。
これを用いることで、値を保持できる最小のデータ型に「数値」のままで変換してくれます。
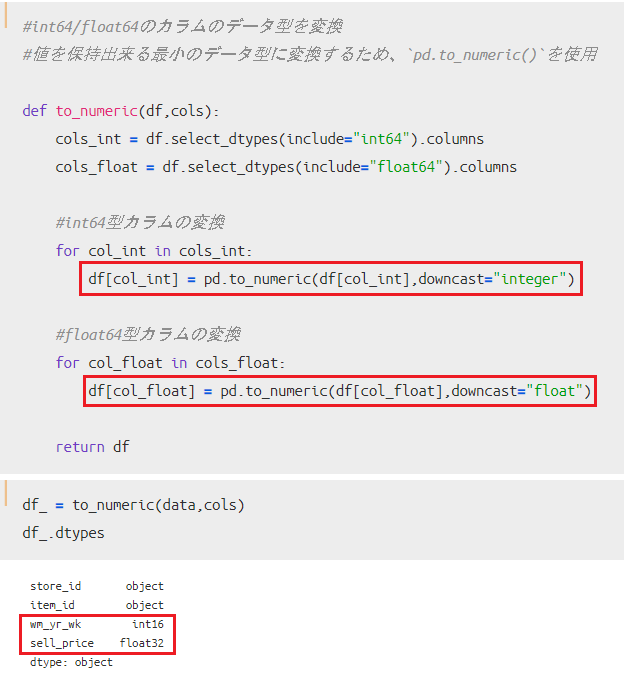
この処理をした結果、最終的にカラムのデータ型が変換されたのがわかるかと思います。
「int64」が「int16」に変換され、「float64」が「float32」に変換されていますね。
この変換処理によって、結果的にどのくらいデータサイズを圧縮できたのか確認していきます。
データ型変換後の「データサイズ」を確認する
データサイズの確認方法については以前の記事で紹介しているので、今一つわからない方はそちらを参考にしてみてください。
まずデータサイズを確認しておきましょう。

次に、先ほどの自作関数にデータサイズを確認するコードを付け加えます。

その結果、データ型を変換したことで、データサイズが約65.2 MBも削減されたことがわかりますね。
このようにしてデータを軽くする前処理は、モデル構築してデータを訓練させるフェーズで活きてくるので、テクニックの一つとして抑えておきましょう。
さいごに
今回はpythonのpandasを用いて、データ型の確認方法や抽出・圧縮方法を中心に見てきました。
アルゴリズムの選択やモデル手法に目が行きがちですが、そもそも扱う対象データにも目を向けることが大切なので、前処理のテクニックとしても使ってみてください。
では今回はこのへんで。