【Python Coding】pandasでSeriesを作成する方法


こんにちは、TAKです。
今回は、pythonのpandasを用いて「Series型」のデータを作成する方法を紹介していきたいと思います。
僕がpythonを勉強し始めた頃は「DataFrameとSeriesの違いって何?」「Seriesを知っておくと何が便利なの?」といった疑問を抱いていました。
そこで今回は、Series型データの作成方法を中心に紹介しつつ、DataFrame型との違いやSeriesを学ぶ必要性について触れていきます。
【こんな人に読んで欲しい記事です】
● pandasを使って「Series型」データを作成出来るようになりたい方
● pandasで作成出来る「DataFrame型」と「Series型」の違い・必要性を知りたい方
必要ライブラリのインポート
まず最初に今回使うライブラリをインポートしておきます。
メインはpandasとなりますが、一応numpyもインポートしておいてください。
pandasを用いて作成するSeriesは「numpyで作成する配列」と似ている点があるので、比較するためにもnumpyをインポートしておきます。
Seriesをゼロベースで作成する方法①
ではSeriesを実際に作成していきます。
Series型は、`pd.Series()`を使うことで簡単に作成することが可能です。
特に何も意識せず、Seriesを作ると以下のようになります。
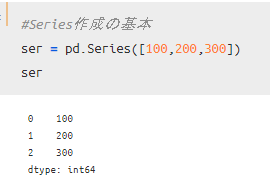
「100,200,300」というデータが表示され、その左側に「0,1,2」とラベルみたいなのがくっついてますね。
このラベルのことを「インデックス(index)」と呼びます。
numpyを使って、同じように「100,200,300」のデータを作成したのが以下です。
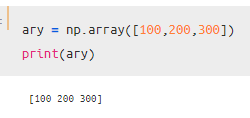
先ほどのSeriesと比べてみると、インデックスがないですね。
このように、感覚的に説明すると一次元配列にインデックスを加えたものが「Series」となります。
Seriesをゼロベースで作成する方法②
先ほどは何も意識せずに、データだけ指定してSeriesを作成しました。
今度は、インデックスや名前を指定したSeriesを作成してみようと思います。
シンプルな例ですが、あるショップAにおける1月から3月までの売上を示しているデータを仮定しましょう。
先ほどの「100,200,300」が売上に相当し、インデックスとして「Jan,Feb,Mar」を追加、名前「Shop A」を追加して作成したSeriesが以下となります。

最初に作成したSeriesと比べて、indexやnameといった引数を追加するだけです。
その結果、index部分が指定した月となり、name部分がShop Aとなっているのがわかりますね。
Seriesを辞書型を用いて作成する方法
続いて、辞書型を用いてSeriesを作成する方法も紹介しておきたいと思います。
DataFrameの場合もそうですが、個人的には辞書型を使うのが感覚的にわかりやすくて好きです。
辞書型を用いて作成したSeriesが以下となります。
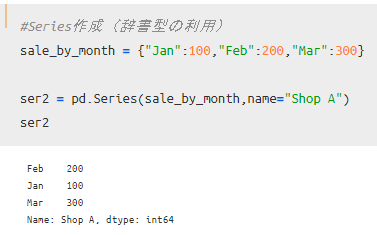
辞書型はリストと異なり、順番に意味を持たない(組み合わせに意味を持つ)タイプなので、順序は先ほどと異なっていますが、並び以外は同じ結果となっていることがわかります。
作成したSeriesが「Series型」であることの確認
ここで、作成したSeriesの「型」を確認しておきます。
Seriesとして作成したので当然「Series型」になっていないと困りますよね。
後ほど、DataFrameとの比較でも「型」を確認していくので、一度ここで確認作業をはさみます。
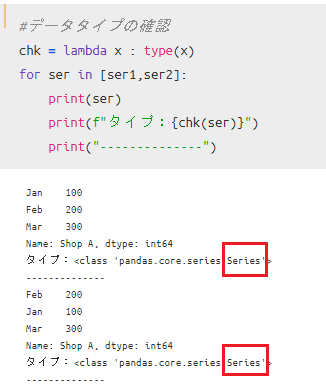
コードの書き方は自由ですが、先ほど作ったser1・ser2ともに「Series」であることが確認出来ました。
DataFrameとの関連性
ここまで、Seriesの作成方法を紹介してきましたが、やはり気になるのは「結局Seriesって何に役立つの?」という疑問かと思います。
この疑問に明確に答えた記事を僕は見たことがないので、もしかしたら当たり前(?)のことなのかもしれませんが、個人的には「データ分析の精度を上げる」ためにも、Seriesの理解は不可欠と思っています。
どういうことかというと、データ分析は対象データをpandasで読み込み、DataFrame化することから始まります。そして、データへの理解を深め、必要に応じて特徴量を設計し、モデルを構築・学習して最終的には予測するといった複雑なプロセスを踏むことになります。
そのプロセスにおいて頻繁に行われるのが「DataFrameの切り出し」や「特定の特徴量(カラム)へのアクセス」です。この切り出しやアクセスで操作している対象データこそが「Series」なのです。
つまり、「DataFrameというのはSeriesの集合体であり、データ分析時にはDataFrameの構成要素であるSeriesを頻繁に扱うため、Series操作への理解は必要不可欠」というのが、感覚的な説明となります。
厳密には、Seriesは「一次元のデータ構造」であり、DataFrameは「二次元のデータ構造」と言えます。pandasのドキュメントにもそのような記載があるので、参考にしてみてください。
Series is a one-dimensional labeled array capable of holding any data type (integers, strings, floating point numbers, Python objects, etc.). The axis labels are collectively referred to as the index.
DataFrame is a 2-dimensional labeled data structure with columns of potentially different types. You can think of it like a spreadsheet or SQL table, or a dict of Series objects. It is generally the most commonly used pandas object.
pandasドキュメントより
DataFrameとSeriesの比較
最後に、シンプルな例を用いてDataFrameを作成し、そこから切り出したデータが本当にSeriesとなっているのかを確認してみたいと思います。
先ほどは、ショップAだけを想定していましたが、これにショップBを追加した「1月から3月までの売上」を示したデータを想定してみます。
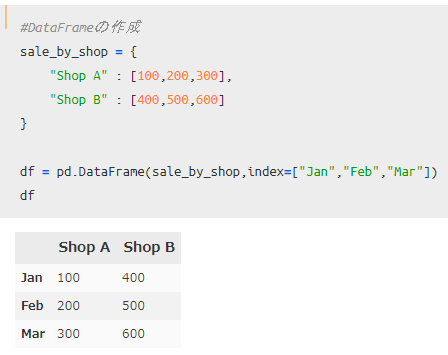
先ほどのShop AにShop Bが追加され、DataFrame型になっていることがわかりますね。
このDataFrameから「Shop A」だけを抽出した結果を表示させてみましょう。

すると、最初の方に示した「ser1」と同じような結果になっていることがわかるかと思います。
DataFrameから抽出したデータがSeriesになっていることを確認した結果が以下のコードです。

以上はシンプルな例でしたが、「DataFrame」から切り出したデータが「Series」になっていることが確認出来ましたね。
さいごに
今回は、pythonのpandasを使って「Series」を作成する方法を紹介してきました。
Series単体で使うことはさほど多くないかもしれませんが、DataFrameと合わせて使えるようにすることで、データ分析の幅が広がると思うので、是非使えるようにしてみてください。
pandasで「DataFrame」を作成する方法は以下の記事を参考にしてください。
では今回はこのへんで。