【Python Coding】seabornでカーネル密度推定を作る方法を解説します


こんにちは、TAKです。
前回に引き続き、今回もpythonのseabornを使った可視化について解説していきます。
今回は「2D KDE Plot(二次元カーネル密度プロット)」について、pythonのJupyter Notebookを用いて紹介していきます。以前紹介した「カーネル密度推定」と「散布図」をミックスしたようなものと思って頂ければOKです。
1. pythonを用いた可視化方法を学んでいきたい方
2. pythonを用いて「2D KDE plot」を描けるようにしたい方
seabornを用いたデータ可視化 | 2D KDE Plot
必要ライブラリのインポート

今回必要となるライブラリは以上の4つです。
最初の4行は、データを読み込んで可視化する場合のお馴染みのコードです。
最後の1行は、今回使うアヤメのデータを呼び出すために必要なコードです。
利用データの確認
今回使うデータはアヤメのデータセットです。
これは、データサイエンスや統計学の勉強をしている方にはお馴染みのデータセットなのですが、「アヤメ」という花の3つの品種について、「がく片の長さ」「がく片の幅」「花びらの長さ」「花びらの幅」の各データが記録されたデータです。
データセットの構成は以下のようになっています。
● sepal length(cm):がく片の長さ
● sepal width(cm):がく片の幅
● petal length(cm):花びらの長さ
● petal width(cm):花びらの幅
● target:アヤメの品種(Setosa、Versicolor、Virginica)
データの準備(STEP1:データセット読込)
では実際にpandasを用いてアヤメのデータセットを読み込んでいきます。
まず最初に、データセットを以下のようにして読み込みます。
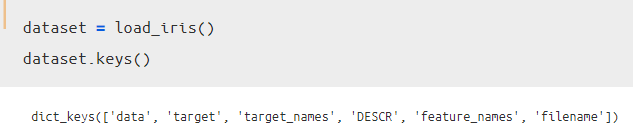
データセットの構成は上記のような辞書型になっています。
今回主に使っていくのは以下の3つです。
● 特徴量の名前が格納されている「feature_names」
● 目的変数が格納されている「target」
データの準備(STEP2:説明変数のデータフレーム化)
次に説明変数と特徴量を以下のように読み込みましょう。
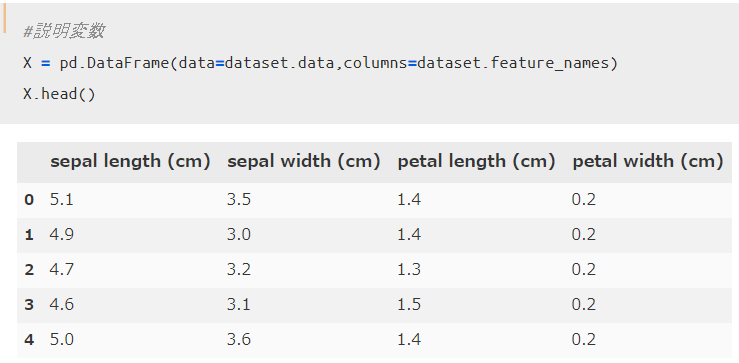
各4つの特徴量が適切に取得出来ていることがわかりますね。
データの準備(STEP3:目的変数のシリーズ化)
説明変数の設定が出来たので、目的変数について見ていきます。
各特徴量を持つ品種が何かを意味する目的変数は、targetに格納されているので、これをSeries型として読み込んでおきます。

先頭5行についてはすべて「0」となっていますが、これは機械学習モデルを構築しやすいように、既にラベルの変換が行われているためです。つまり、「Setosa → 0」「Versicolor → 1」「Virginica → 2」と変換した後の結果がtargetに格納されているということです。
今回はモデル構築ではなく、データ可視化が目的なので理解を深めるために品種名に戻しておきます。
クラスラベルの変換として下記コードを実行すればOKです。
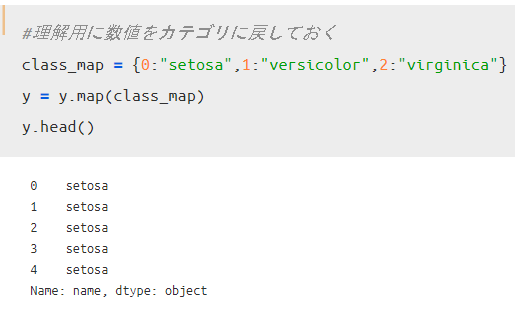
この結果、ラベル名が適切に品種名になっていることが確認出来ました。
クラスラベルの変換方法について今一つわからない方は、下記記事で紹介しているので参考にしてください。
データの準備(STEP4:データの結合とカラム名変換)
説明変数と目的変数について準備が出来たので、これらを統合したデータセットを作っておきます。
以下のコードで結合が可能です。
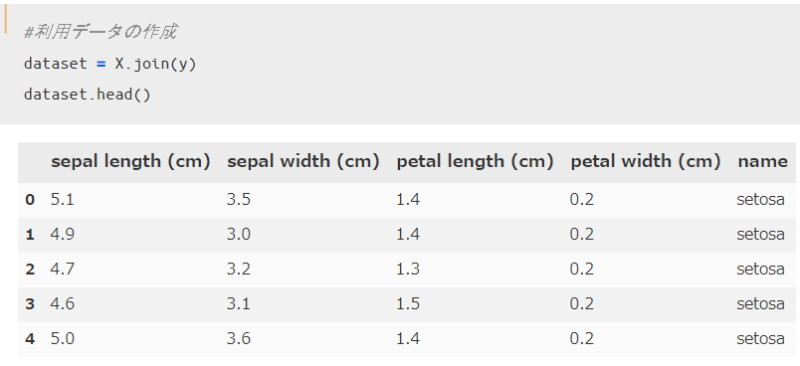
以上でOKなのですが、カラム名(列名)に(cm)と入っていて個人的に見にくいので、下記コードを追加することでシンプルなデータセットにしておきます。これは好みなのでなくても大丈夫です。
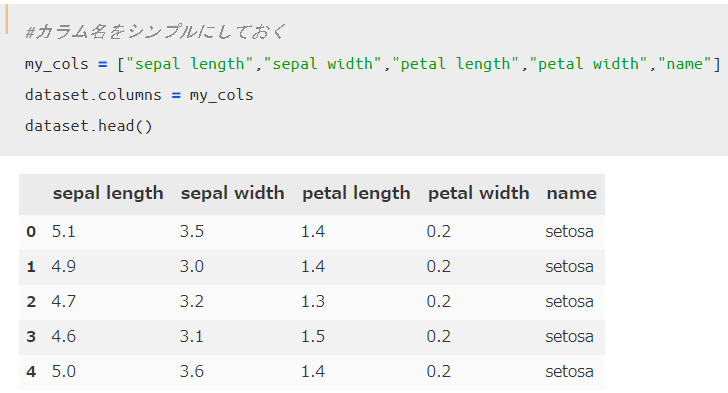
以上でデータ可視化用のデータが出来上がりました。
データ可視化①
では実際にseabornを用いて2D KDE plotを描画していきましょう。
2D KDE plotは「散布図」と同じように、2変量データ(量的変数×量的変数)の場合に使える方法なので、特徴量として「petal length(花びらの長さ)」と「sepal width(がく片の幅)」を使って2D KDEを描くことにします。僕は特徴量の手打ちが面倒なので、いつものようにしてリスト化しておきます。

そして、以下のコードを実行することで、2D KDE plotを描画することが可能です。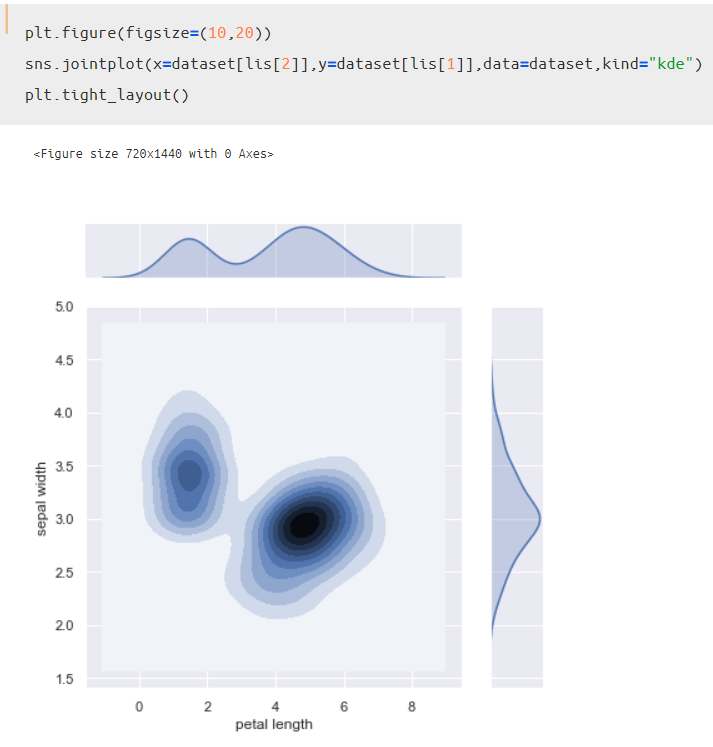
ポイントは以下3つです。
● 引数としてxとyの値、そして対象となるデータを指定する必要がある
● kind引数に「kde」を指定することで、発生確率の高い分布の色が濃く表示される
これで2D KDE plotを描くことが出来ましたね。
x軸(petal length)の上側、y軸(sepal width)の右側にカーネル密度推定が描かれ、データの重なり具合に応じて中央に色が塗られているのがわかるかと思います。
アヤメの3品種が混ざったデータ分布とはなりますが、以下のデータが観測される確率が高いと言えます。
2. petal lengthが4cm~6cm、sepal widthが3cmの組み合わせとなるデータ
ちなみに、引数kindに何も指定しないデフォルト時には、以下のように散布図みたいな表示がされます。
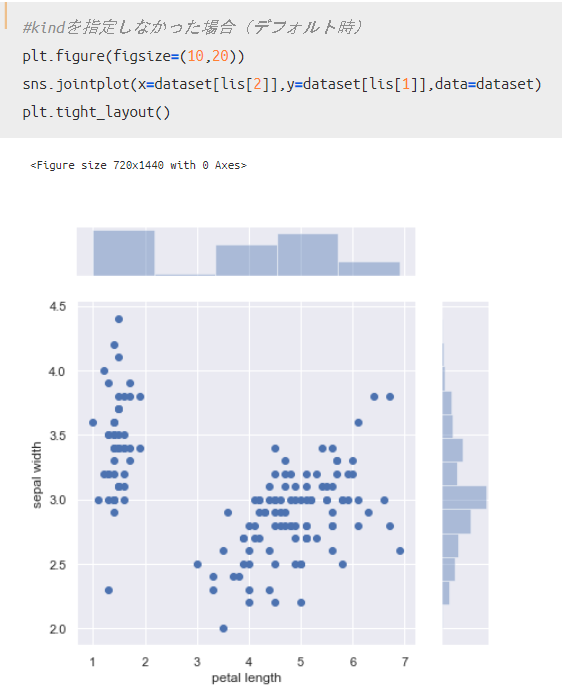
散布図を用いると各データの散らばり具合もわかって便利なので、必要に応じて使い分けてみてください。
ここでのデータは3品種すべてが混ざっている状態だったので、以下では品種別にわけてみたいと思います。
データ可視化②
では実際に品種別にグラフを描いてみます。データセットには150個分のデータがまとめて格納されているので、まずは品種別に50個ずつデータを分割していきます。50個ずつ適切にデータ分割出来ればどんな方法でもOKです。
僕であれば以下のような方法でデータを分割・確認します(前回同様)。
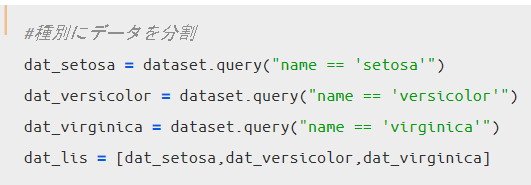
データの分割が出来たので、品種別に2D KDE plotを描いてみましょう。
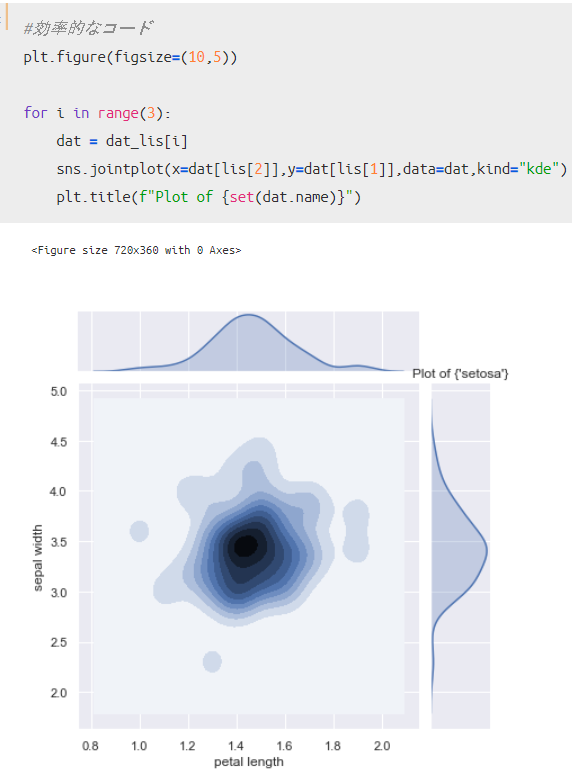


結果、品種別に2D KDE plotが描けたことがわかります。
この結果は、先ほどの「データ可視化①」で得た結果を分解していることがわかります。
2. petal lengthが4cm~6cm、sepal widthが3cmの組み合わせとなるデータ → 「Setosa以外」
量的変数同士の分布を可視化する手段としては散布図が代表的ですが、データ分布として発生しやすい組み合わせを把握する観点からは、この2D KDE plotも使いやすいのでオススメです。
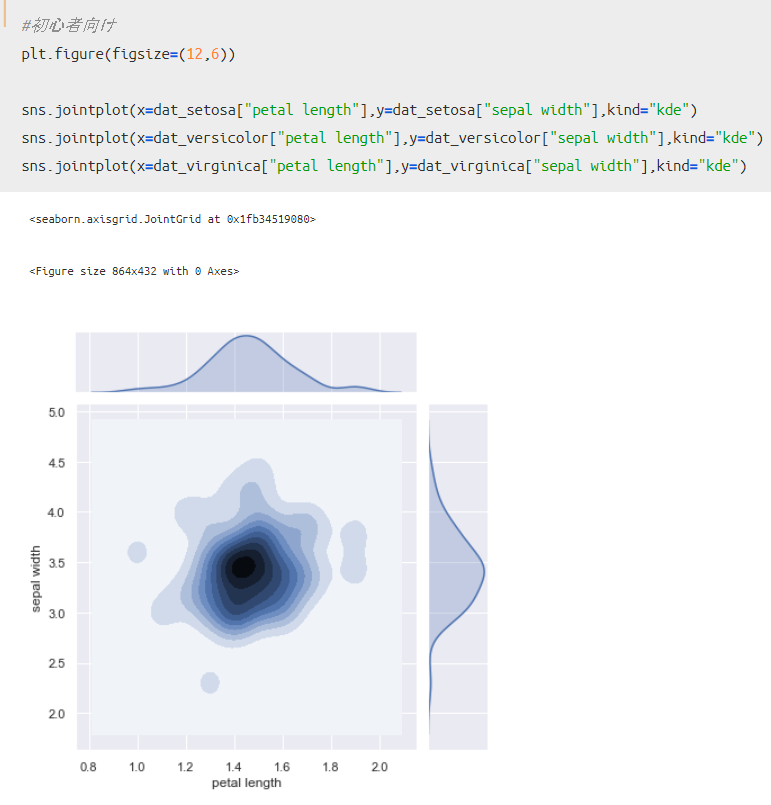
ちなみに、上記のコードがよくわからないという方は、以下のように書いてもOKです。
同じ結果が得られることがわかるかと思います(先頭結果のみ表示)。
まとめ
いかがだったでしょうか?
今回は可視化手法として「2D KDE plot」について紹介してきました。量的変数同士の可視化に使える方法なので、散布図と合わせて使えるようにしてしてみてください。
では今回はこのへんで。