【Python Coding】整然データ(Tidy Data)


こんにちは、TAKです。
前回「データ分析に必須の整然データ」について解説したので、今回は実際にpythonを使ったcodingを紹介していきたいと思います。
1. 整然データ(Tidy Data)をpythonで実装してみたい方
2. データサイエンスの勉強をしている方
3. データ分析力を高めたいと考えている方
必要に応じて、みなさんもローカル環境で実装トライしてみてくださいね。
【Case2】2020年1月~12月の製品別売上高が記載された雑然データ
【Case3】2020年1月~12月の製品に係る売上高・売上原価・粗利率が記載された雑然データ
【Case1】Python Coding
必要ライブラリのインポート(共通)
まずはpythonで必要ライブラリをインポートしていきましょう。
と言っても、今回はpandasのインポートのみでOKです。
データセットの準備&確認
具体例の一つ目は、冒頭で説明したような下記企業データが格納されたデータを使います。
【CSVファイルイメージ】

なぜ雑然データなのか今一つわからない方は、前回記事を参考にしてみてください。
Data Frameとして格納
まずCSVファイルを読み込み、Data Frame形式として格納します。
ここは読み込むファイルを指定するだけなので、やり方さえ理解していれば難しくないですね。
※変数名は自分の好きなように変更してみてください。
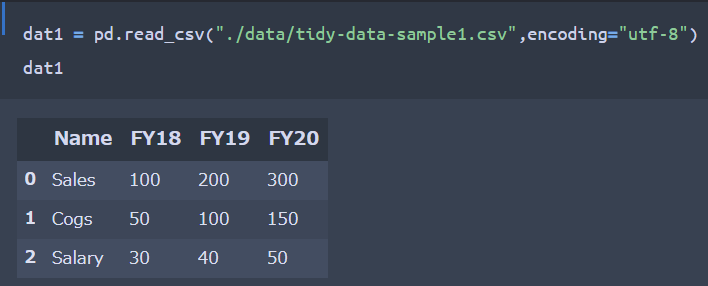
CSVファイルと同じデータがData Frameとして格納されたことが確認出来ますね。
Tidy Dataに変換
では今回のメインである「雑然データを整然データに変換」する作業をしていきます。
ポイントは、pandasのmeltメソッドを用いる点です。
結論から言うと、下記Codingのみで雑然データから整然データへの変換が可能となります。

ポイントをまとめるとこのようになります。
整然データに変換するために使用
frame ・・・ 変換対象となるデータフレームを指定
id_vars ・・・ メインとなる軸を指定。この例では「Name」が該当
value_vars ・・・ 集計対象の値の軸を指定。この例では金額を自動集計すれば問題ないので不要
var_name ・・・ 変数列の名前を任意で指定。この例ではデフォルト指定とした(=variable)
value_name ・・・ 値列の名前を任意で指定。この例では「Amount」と指定とした
【Case2】Python Coding
データセットの準備&確認
具体例の二つ目は、冒頭で説明したような下記企業データが格納されたデータを使います。
【CSVファイルイメージ】
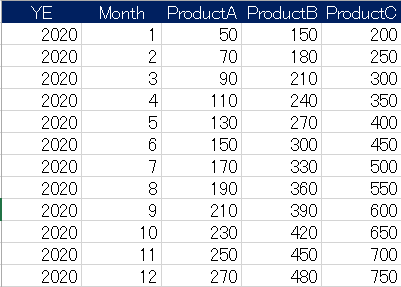
これも雑然データなのでデータ分析の観点からは扱いにくいですね。
Data Frameとして格納
先ほど同様に、まずCSVファイルを読み込み、Data Frame形式として格納します。
※変数名は自分の好きなように変更してみてください。
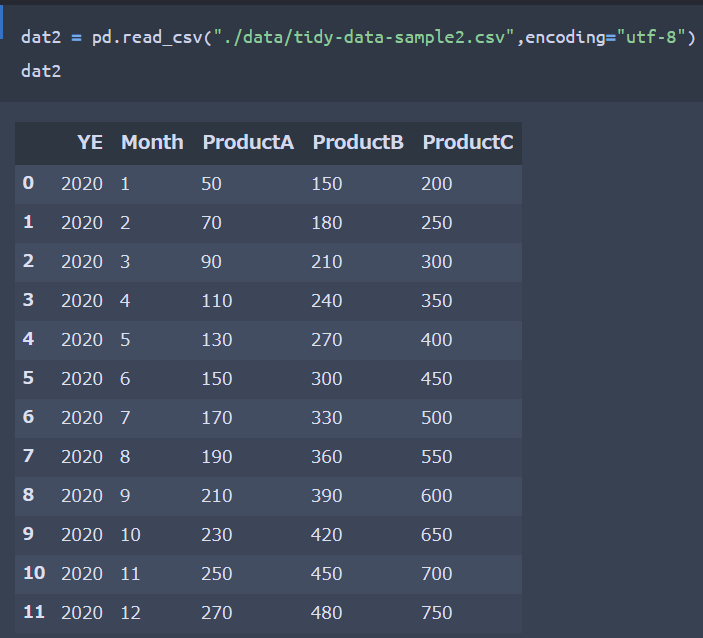
CSVファイルと同じデータがData Frameとして格納されたことが確認出来ますね。
Tidy Dataに変換
次に「雑然データを整然データに変換」する作業ですね。
先ほどの例と同様にCodingすればOKなので、わかる人はまず自分で実装してみてください。
雑然データから整然データへの変換Codingは下記のようになります。
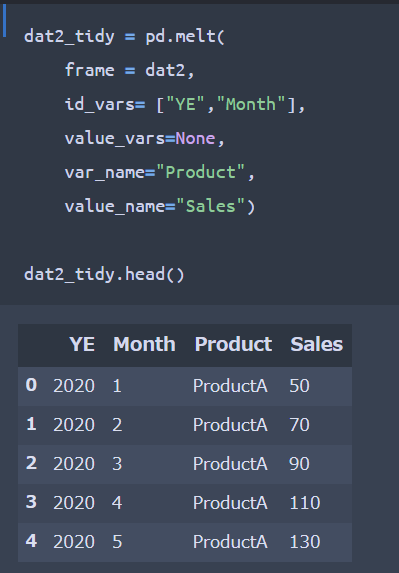
※整然データに変換した後のデータ数が縦長になるため、headを用いて5個分のみ表示しています。
ポイントをまとめるとこのようになります。
整然データに変換するために使用
frame ・・・ 変換対象となるデータフレームを指定
id_vars ・・・ メインとなる軸を指定。この例では「YE」と「Month」が該当
value_vars ・・・ 集計対象の値の軸を指定。この例では金額を自動集計すれば問題ないので不要
var_name ・・・ 変数列の名前を任意で指定。この例では「Product」と指定とした
value_name ・・・ 値列の名前を任意で指定。この例では「Sales」と指定とした
その他は変数の名前の違い程度なので、変換の仕方自体は同じと言えますね。
【Case3】Python Coding
データセットの準備&確認
具体例の三つ目は、冒頭で説明したような下記企業データが格納されたデータを使います。
【CSVファイルイメージ】

Data Frameとして格納
これも繰り返しとなりますが、まずCSVファイルを読み込み、Data Frame形式として格納します。
※変数名は自分の好きなように変更してみてください。

CSVファイルと同じデータがData Frameとして格納されたことが確認出来ますね。
Tidy Dataに変換
では最後の「雑然データを整然データに変換」する作業をしていきましょう。
先ほど同様、わかる人はまず自分で実装してみてください。
雑然データから整然データへの変換Codingは下記のようになります。

※整然データに変換した後のデータ数が縦長になるため、headを用いて5個分のみ表示しています。
ポイントをまとめるとこのようになります。
整然データに変換するために使用
frame ・・・ 変換対象となるデータフレームを指定
id_vars ・・・ メインとなる軸を指定。この例では「YE」と「Month」が該当
value_vars ・・・ 集計対象の値の軸を指定。この例では「Sales」「Cogs」「Ratio」が該当
var_name ・・・ 変数列の名前を任意で指定。この例では「Name」と指定とした
value_name ・・・ 値列の名前を任意で指定。この例では「value」とした(デフォルト設定)

まとめ
いかがだったでしょうか?
今回は雑然データを整然データに変換することを目的としたCodingを紹介してみました。
ビジネスでは雑然データが多く存在しているので、整然データに変換した上でデータ分析に繋げることが出来れば、業務スピードも大幅にアップします。
是非色んなデータで試してみてください!
また別の機会で「整然データをベースとして、どのようにデータ分析をすればいいか」についても記事を書いていこうと思います。
書籍の紹介
最後に、今回紹介したような「pandas操作」についてスキルを高めたい方向けにオススメの書籍を紹介したいと思います。興味のある方は是非チェックしてみてくださいね。
pandasを使ったデータ分析を中心に紹介されており、辞書代わりにも使えるのでオススメです。
では今回はこのへんで。