整然データ(Tidy Data)とは何か?データ整理に必須の型を身に付けてデータ分析力を上げよう


整然データについて知りたい人「整然データっていったい何?データを扱うのに知っておくと何かいいことあるの?わかりやすく解説して欲しい」
こんな疑問を解決していきます。
整然データは望ましいデータの形式
「データ分析をする時、元となるデータはどのような形式で整理していますか?」
もしこのような質問をされたらみなさんはどのように答えるでしょうか。自分が理解しやすいように整理すれば問題はありません。ただプログラミング言語のPythonやRを使って「データ分析」をする観点から言えば、整然データの形で整理するのが望ましいです。
何も意識せずにごちゃごちゃにデータをまとめていれば、それは雑然データと言われます。本記事では雑然データと整然データの意味を紹介しつつ、両者の違いを具体例を通して紹介していきます。
本記事で整然データを理解すれば、データ分析力が一気に高まりますよ。
本記事の内容
- 雑然データと整然データの違い
- “雑然データ”の形式でデータを整理した場合
- “整然データ”の形式でデータを整理した場合
僕のブログでは【完全ガイド】pythonの学習サイトをレベル別に紹介!【基礎から機械学習・人工知能までのロードマップ】という記事も公開しています。興味のある人は参考にしてみてください。
pythonの学習ロードマップへ整然データとは何か?雑然データとの違いを解説

データの形式には大きくわけて「整然データ」と「雑然データ」の2種類があります。両者の意味合いを具体例を通じて理解していきましょう。
整然データと雑然データの意味
両者の意味を簡単にまとめると以下のようになります。
- 雑然データ(Messy data):データが散らばっていて分析しにくいデータの形式
- 整然データ(Tidy data):データがまとまっていて分析しやすいデータの形式
言葉だけだとイメージしにくいので、具体例を見ていきます。
カフェの来店客数データをまとめてみよう
以下のような具体例を想定してみます。
全国展開するカフェがあります。主要エリアである東京本店と大阪支店の責任者から「2022年1月から3月」の3ヶ月の来店客数に関するデータを取り寄せました。
------------
【東京本店】
・2022年1月:1,500人、2月:1,300人、3月:2,000人
【大阪支店】
・2022年1月:1,000人、2月:800人、3月:1,300人
------------
このデータを分析しやすいように「表」でまとめてみてください。
こんなケースがあった場合、みなさんならどのようにデータを整理するか、一度考えてみてください。どのようにデータを整理したかを見れば、それが「雑然データ方式」なのか「整然データ方式」なのかがわかります。
もし以下の表のように整理された人は、データ分析に慣れている人かと思います。パッと見てわかりやすいですし、一覧性に富んでいますからね。
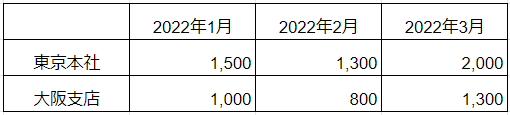
ただこれ、実は「雑然データ」による分類方法となります。
「整然データ」で表をまとめると、以下のようになります。
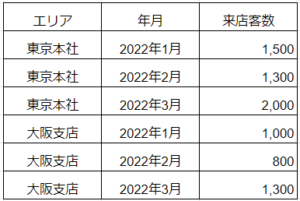
なんだか見慣れない形式ですね。
この点を踏まえた上で、両者の特徴を詳しく解説していきます。
整然データは「見にくいけどデータ分析はしやすい」
整然データとは、データがまとまっていて分析しやすい形式とお伝えしましたが、厳密には定義があります。
ハドリー・ウィッカム氏という方が提唱した「データ分析をしやすくするために整理した表形式のデータ」を整然データと言うのですが、具体的には以下4つの条件を満たす必要があるのです。
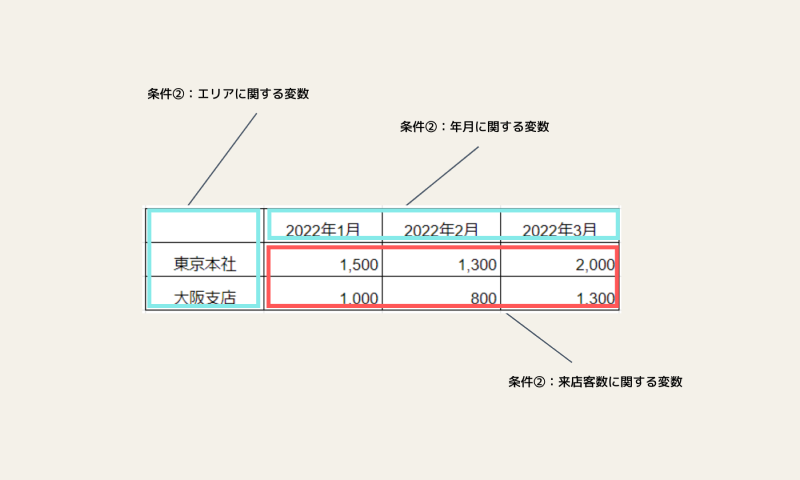
- 条件①:ある1つの観測ユニットについてまとめた表
- 条件②:それぞれの列は「変数」を表す
- 条件③:それぞれの行は「観測値」を表す
- 条件④:1つのセルには1つのデータのみが格納されている
先ほどの例で言えば、カフェの来店客数に関するデータをまとめた表(条件①)で、「エリア」「年月」「来店客数」という列はそれぞれが変数になっています(条件②)。さらに、各行は1つずつの観測データ(条件③)となっていて、1つのセルには1つのデータが格納(条件④)されている形式です。
この4条件を満たしているので、先ほどの表は「整然データ」ということが出来るのです。中でも、条件②と③が重要。これを図示したものが以下のイメージ図です。

整然データの形式でまとめると、データ分析にはとても役立ちます。一方で、語弊を恐れずに言うならば表としては見にくさもあります。そのため、プレゼン資料など理解してもらうための表を作る観点で言えば「雑然データ」の方が優れています。
一方で、PythonやRを使ってデータ分析を進める観点から言えば、整然データの方が圧倒的な力を発揮してくれるのです。なぜなら、データの構造とデータの意味が一致しているから。
例えば、エリア別の来店客数を知りたい場合は、1列目(エリア)と3列目(来店客数)のデータを使えばOKです。もし月別の来店客数を知りたい場合には、2列目(年月)と3列目(来店客数)のデータを使えばいいのです。
当たり前と思われるかもしれませんが、これが出来るのも「データの構造」と「データの意味」が一致しているからこそなのです。この特徴はぜひ知っておいてください。
雑然データは「見やすいけどデータ分析はしにくい」
続いては「雑然データ」。
整然データとあわせて特徴を紹介してきたので繰り返しにはなりますが、雑然データはパッと見わかりやすい構造となっています。そのため、プレゼンなどで誰かに見せたり理解してもらうためには望ましい形式と言えます。
一方で、データ分析の観点からは今一つ。その理由を図示したものがこちら。
データ分析で使うために必要な「変数」があちこちに分散していますよね。これだと、PythonやRを使うときに非常に使いづらい。変数の取得がしにくいというのは、データ分析では致命的です。
こういった理由で、データ分析をする場面では「整然データ」が望ましいのです。
まとめ:整然データはPythonやR言語でデータ分析力を高めるためにも絶対に知っておくべき型!

本記事をまとめます。
- データを整理する方法には「整然データ」と「雑然データ」がある
- 整然データは少し見にくいが、データ分析しやすい型
- 雑然データは見やすくて理解しやすいが、データ分析はしづらい型
- PythonやR言語を使ってデータ分析する時は「整然データ」を意識しよう
こんな感じですね。
整然データでデータ分析をしやすくすれば、データ分析の幅も広がり分析力も向上します。ぜひ本記事で紹介した内容を理解して実践してみてください。
冒頭でも紹介しましたが、データ分析に最適なpythonの学習方法を【完全ガイド】pythonの学習サイトをレベル別に紹介!【基礎から機械学習・人工知能までのロードマップ】でまとめています。良ければあわせて読んでみてください。
【完全ガイド】pythonの学習サイトをレベル別に紹介!【基礎から機械学習・人工知能までのロードマップ】
pythonを極めたいすべての人に贈る学習ロードマップ。おすすめの学習サイトをレベル別に紹介しているので、pythonのレベルをあげていきたいと考えるすべての人に読んで欲しい記事です。これさえ読めば、自分に合っている学習方法やこれから目指すべき方向性がわかります。pythonライフ、楽しんでいきましょう。