【Python Coding】pandasの「apply」を使って関数を適用する


こんにちは、TAKです。
今回は、pythonのpandasを用いてデータフレーム自体に関数を適用する方法を紹介していきます。
「データフレーム自体に関数を適用するってどういうこと?」と思われるかもしれませんが、今の時点ではデータフレームを構成している行列の値に対して関数を適用していくイメージと思ってもらえればOKです。
【こんな人に読んで欲しい記事です】
● pandasの「apply」を使ってデータフレームの行列値に関数を適用出来るようになりたい方
● データフレームに対して色々な加工を出来るようにしたい方
今回はpandasの「apply」を中心に解説していきますが、似ている方法「applymap」についても最後の方で簡単に紹介したいと思います。
【pandas】データフレームの行列に関数を適用する「apply」

必要ライブラリのインポート(共通)
まず最初に、今回使うライブラリをインポートしておきます。
pandasメインとなりますが、numpyも使うので合わせてインポートしておきます。
また、アヤメデータを使おうと思うので、sklearnもインポートしています。
利用データの作成
今回もアヤメデータを使っていきます。
データ自体は何でもいいですが、カテゴリデータが含まれていないデータセットの方が理解しやすいかなと思い、このデータセットにしています。


データ型もすべて数値型になっているのがわかりますね。
説明変数部分だけをデータフレーム化したこのデータを用いて、applyの使い方を見ていきましょう。
applyの基本①|numpyと組み合わせる
まず、一番基本となるコードの書き方は`df.apply()`となります。
「既存のデータフレーム(df)に対してカッコ内の関数を適用(apply)していくよ」といったニュアンスです。
最初に、「numpy」と組み合わせた基本的な使い方を紹介していきます。
各カラムごと(行方向)の合計値を求めたい場合には、以下のようなコードで実現出来ます。

行方向ではなく、各観測値ごと(列方向)の合計値を求めたい場合には、以下のようなコードとなります。
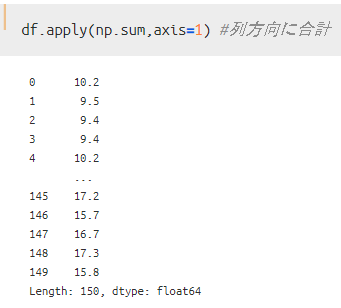
このように、applyのカッコ内でnumpyを使うことが出来ます。
ここでは合計のみを取り上げましたが、その他方法(平均値や最大値など)も当然使えます。
applyの基本②|ラムダ関数と組み合わせる
次に、ラムダ関数と組み合わせた方法を紹介していきます。
個人的には、先ほどのnumpyを使った方法よりも、ここで紹介するラムダ関数の方が使用頻度が高い気がします。ちなみにここではラムダ関数を使っていますが、通常の関数でもOKです。
早速具体例を見ていきましょう。
理解しやすいように、アヤメデータの全データに「2」だけ加算するシンプルな例を考えてみます。
以下のように、ラムダ関数を定義して、applyを使って呼び出すだけでOKです。
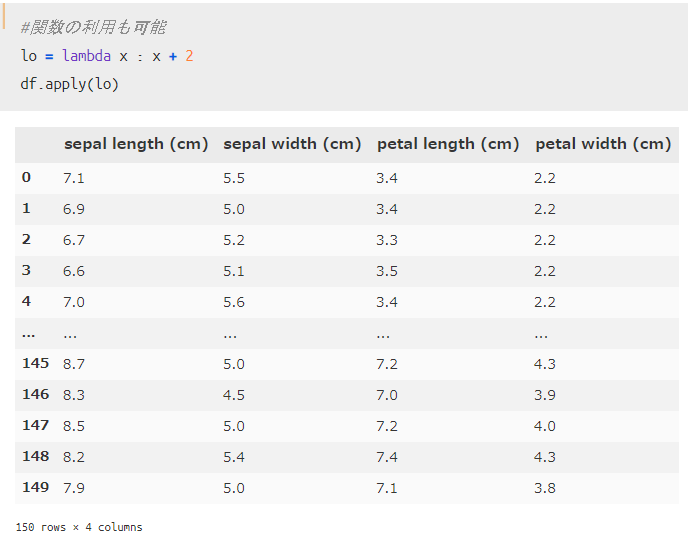
確認のために、「加工後のデータフレーム」と「元々のデータフレーム」の差を取ってみましょう。
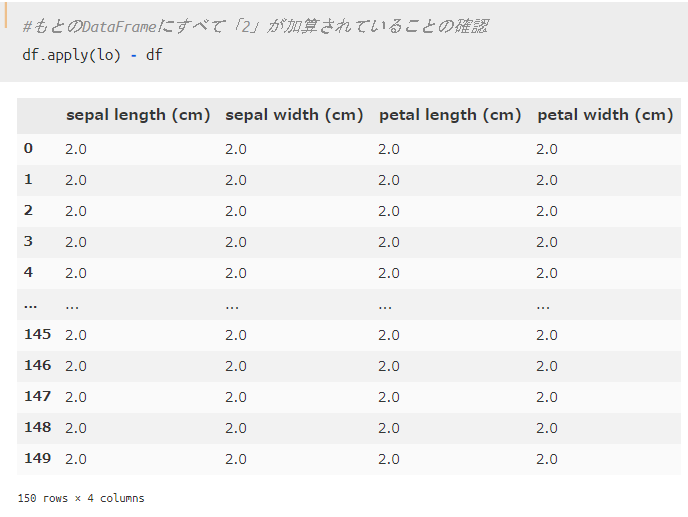
すると、すべて「2」となっていて、適切にデータフレームの加工が出来ていることがわかりますね。
applyの実践的な使い方
「apply」の基本的な使い方は以上となりますが、もう少し実践的な方法を紹介しておきます。
「applyは結局どのような場面で使えばいいの?」と悩まれている方は、以下コードを参考にしてイメージを膨らませてもらえればと思います。
今回のデータセットで出来ることと言えば、例えば「標準化」があります。
標準化とは、データの平均を0、標準偏差を1にするデータの変換処理であり、データ分析では前処理などで使われることが多いですね。
「apply」を使うと、以下のようなコードで標準化することが可能です。
(コードの書き方自体は一例です。)
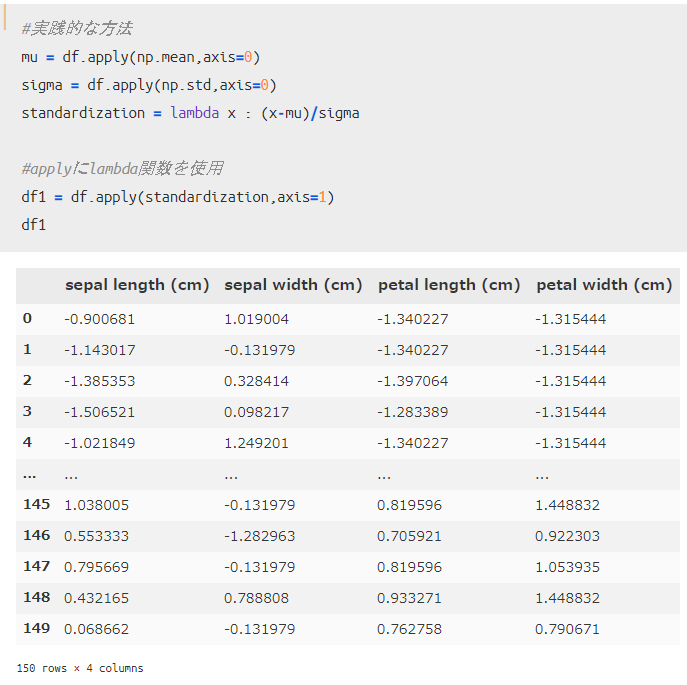
参考程度ですが、sklearnライブラリのStandardScalerを用いて標準化した結果が以下です。
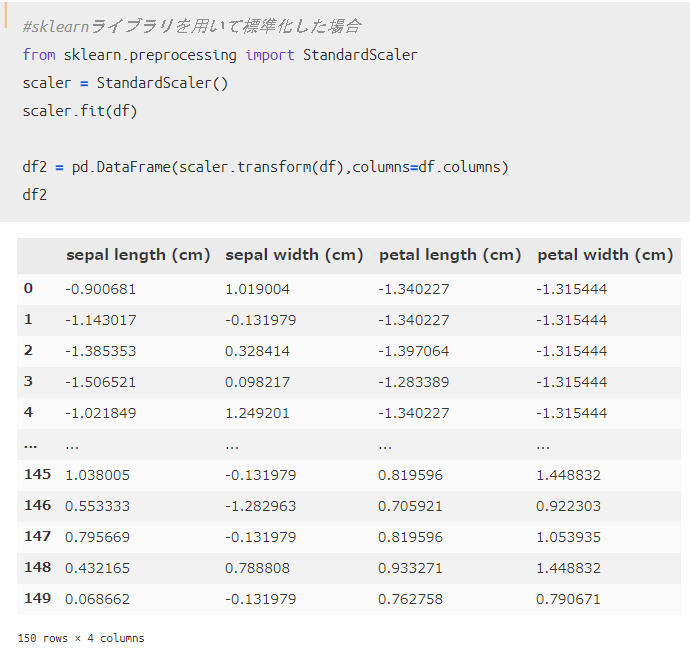
結果を比べてみると、「apply」を用いた場合と「sklearn」を用いた場合で同じ結果になっていますね。
標準化では「sklearn」を使うことが一般的ですが、ライブラリを使わなくても同じ結果を実現出来る「実装力」や「考え方」を身につけておくことは非常に重要になります。
【pandas】データフレームの要素に関数を適用する「applymap」

最後に、「apply」と似ている「applymap」という方法について簡単に紹介しておきます。
簡単に結論だけまとめておくと、以下のような違いとなります。
pandasの「apply」と「applymap」の違い
● apply : データフレームの「行列」に対して関数を適用する場合
● applymap : データフレームの「各要素」に対して関数を適用する場合
アヤメのデータセットはすべて「数値型」データですが、すべての要素を「chk-xxx」という文字列型に変換したい場合を想定してみましょう。以下のようなコードで実現出来ます。
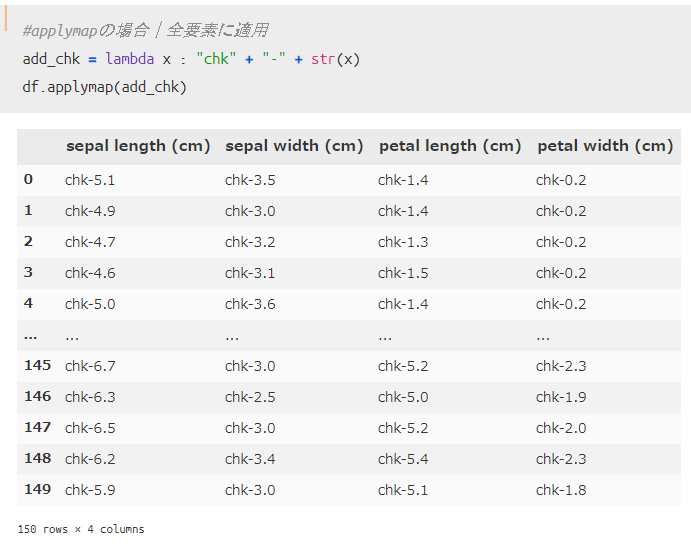
上記結果からわかるように「すべての要素」を対象として関数を適用することが出来ました。
個人的には、「apply」ほど使用頻度は高くないかなといった印象ですが、知っておくと便利なので参考にしてみてください。
まとめ
今回は、pythonのpandasを用いてデータフレームに関数を適用する「apply」「applymap」という2つの方法を紹介してきました。
データフレームを加工する手段として、是非使えるようにしてみてください。
では今回はこのへんで。