【Python Coding】pandasでデータフレームをグループ化する方法


こんにちは、TAKです。
今回は、pythonのpandasを用いて「データフレームをグループ化」する方法を紹介していきます。
データをグルーピングする必要性やグルーピング方法がわかれば、データ分析の幅が広がるので、分析力をアップさせたい方は参考にしてみてください。
【こんな人に読んで欲しい記事です】
● pandasを使って、データフレームのグループ化が出来るようになりたい方
● データフレームのグループ化の必要性や活用方法が今一つわからない方
必要ライブラリのインポート
まず最初に、今回使うライブラリをインポートしておきます。
今回は、pandasがメインですが、データセットとしてアヤメデータを用いるので、sklearnライブラリも一緒にインポートしておきます。
利用データの確認
アヤメというのは花の名前で、3つの品種に関するデータが格納されています。

【アヤメデータに格納されている内容】
● sepal length(cm):がく片の長さ
● sepal width(cm):がく片の幅
● petal length(cm):花びらの長さ
● petal width(cm):花びらの幅
● target:アヤメの品種(Setosa、Versicolor、Virginica)
利用データの作成
sklearnライブラリからアヤメデータを読み込み、分析しやすいように準備していきます。
目的変数が「0,1,2」と分析用に数値変換されているので、今回は理解しやすいように品種名「 setosa、versicolor、virginica 」に戻す処理を加えています。
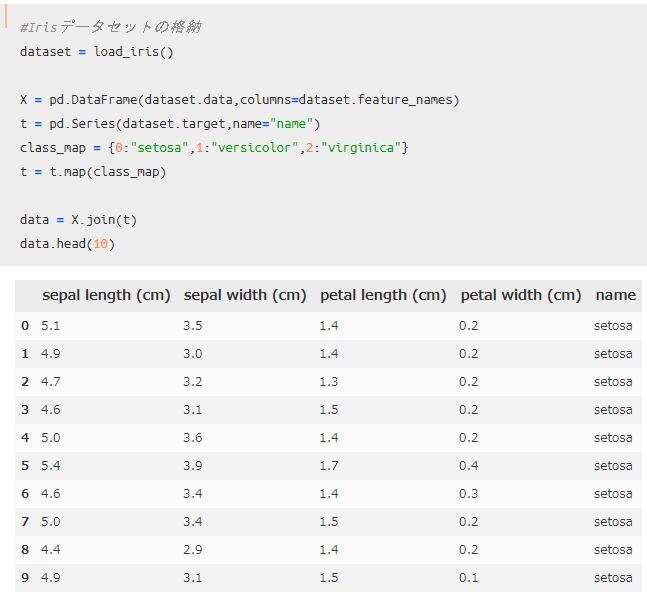
今回の目的は、「グループ化」を用いてアヤメの品種ごとに各データ統計量を確認出来るようにすることです。
上記10行だけ表示したデータフレームを見てもらえればわかりますが、「setosa」に関するデータが10個並んでいますよね。「同じ品種であるsetosaは、一体どういった特徴を持っているのか?」を考える時に、同一カテゴリでグループ化する意義が生まれてきます。
ここではアヤメの品種を例として扱いますが、これ以外にも「顧客別の商品購入高を知りたい」「地域別の売上高を把握したい」「商品カテゴリ別の原価を管理したい」など、「○○別」といった時にグループ化する意味が出てくることを理解しておいてください。
繰り返しになりますが、今回は「品種別」にデータ統計量を見ていきます。
グループ化する方法は「groupby」
pandasを用いてデータフレームをグループ化するためには、`df.groupby()`を使います。
「グループ化」したい対象を引数として指定する必要がありますが、それだけでは以下のように何も出力されません。

これは、「品種別(name)」にぎゅっとまとめることには成功していますが、どのようにまとめるかを指定していないため、何も表示されないのです。「どのようにまとめればいいか」と言うと、みなさんが知っているような方法(合計や平均など)を使っていけばいいだけです。
品種ごとにグループ化|平均
ここからは、品種別に色々なまとめ方を見ていきたいと思います。
ポイントは、`df.groupby()`の後に各統計量を示すコードを追加する点です。
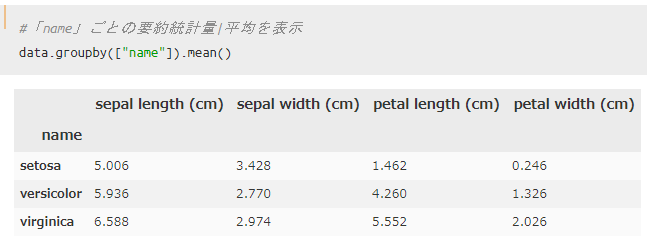
まずは品種ごとに平均を用いてグループ化してみます。
`df.groupby().mean()`を使えばOKです。
品種ごとにグループ化|中央値
次に、中央値を用いてグループ化してみます。
`df.groupby().median()`を使えばOKです。

品種ごとにグループ化|合計
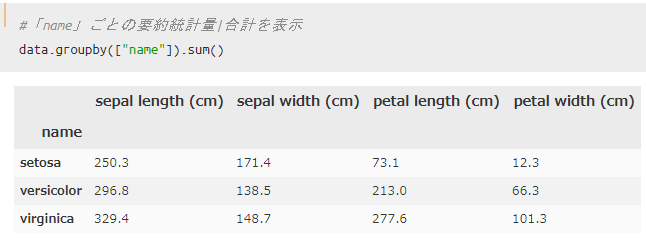
続いて、合計を用いてグループ化してみます。
今回のケースでは合計することにあまり意味はありませんが、売上や集客数のように合計することに意味を持つような場合に使ってみてください。
`df.groupby().sum()`を使えばOKです。
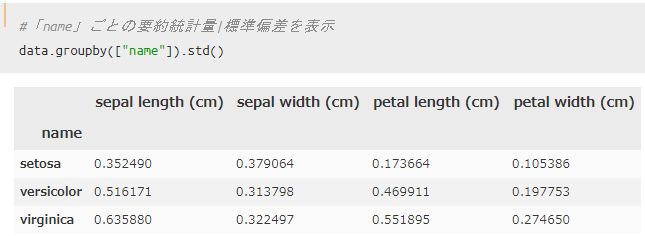
品種ごとにグループ化|分散と標準偏差
続いて、分散や標準偏差を用いてグループ化していきます。
分散の場合は`df.groupby().var()`、 標準偏差の場合には`df.groupby().std()`を使えばOKです。

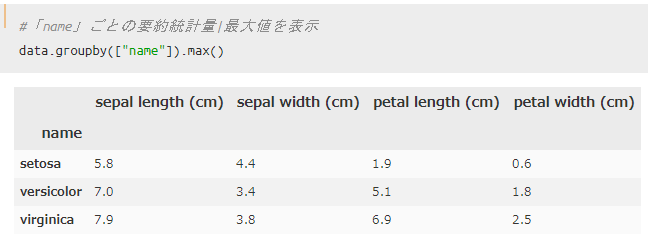
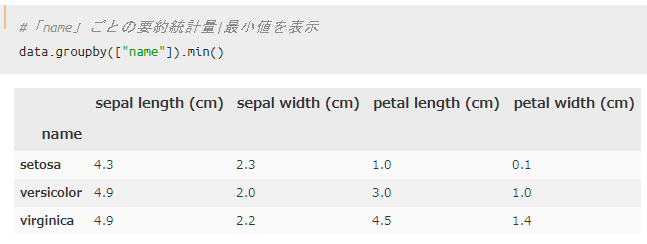
品種ごとにグループ化|最大値と最小値
続いて、最大値と最小値を用いてグループ化してみます。
最大値の場合は`df.groupby().max()`、 最小値の場合には`df.groupby().min()`を使えばOKです。
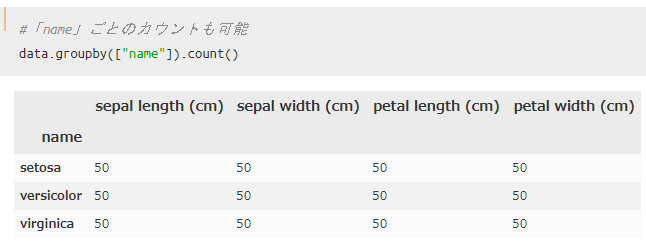
品種ごとにグループ化|カウント
数を数えるカウントも出来るので、あわせて紹介しておきます。
今回、例として用いているアヤメのデータセットは、品種ごとに50個・合計150個のデータから構成されています。それを踏まえた上で下記結果を確認してみてください。
`df.groupby().count()`を使えばOKです。
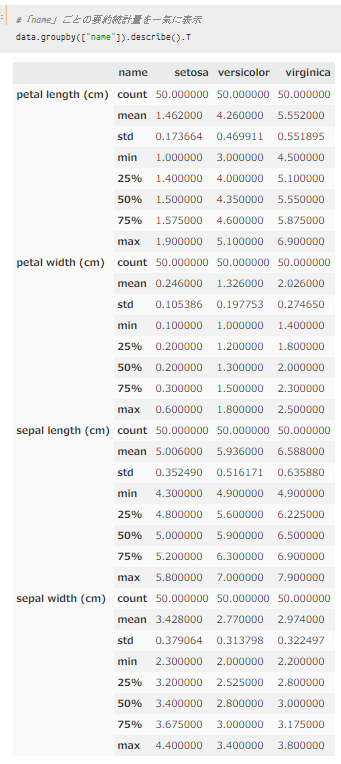
品種ごとにグループ化|要約統計量をまとめて表示
最後に、要約統計量をまとめて表示する方法を紹介します。
データの概観を確認したいような場合に使える方法なので、最初にこの方法を使うのもアリだと思います。
`df.groupby().describe()`を使えばOKです。
以下コードでは、最後に「.T」を用いていますが、これは表示結果を見やすいように転置しているだけなので、気にしなくて大丈夫です。
さいごに
今回は、pythonのpandasを用いて、データフレームをグループ化する方法を紹介してきました。
整然データを用いてデータを管理し、必要に応じてグループ化する方法は非常に重宝するので、是非使えるようにしてレベルアップを図ってみてください。
整然データについては以下の記事で紹介しているので、参考にしてみてください。
では今回はこのへんで。またね~