【Python Coding】混同行列(Confusion Matrix)をコードで理解しよう

こんにちは、たなです。
混同行列はこの図でマスターする!
「混同行列、よくわからない…混乱する…」
今回はそんな悩みを解決していきます。実際にpythonのコードを使って理解を深めていきましょう。でもその前に、以下の図をしっかりとインプットしておいてください。
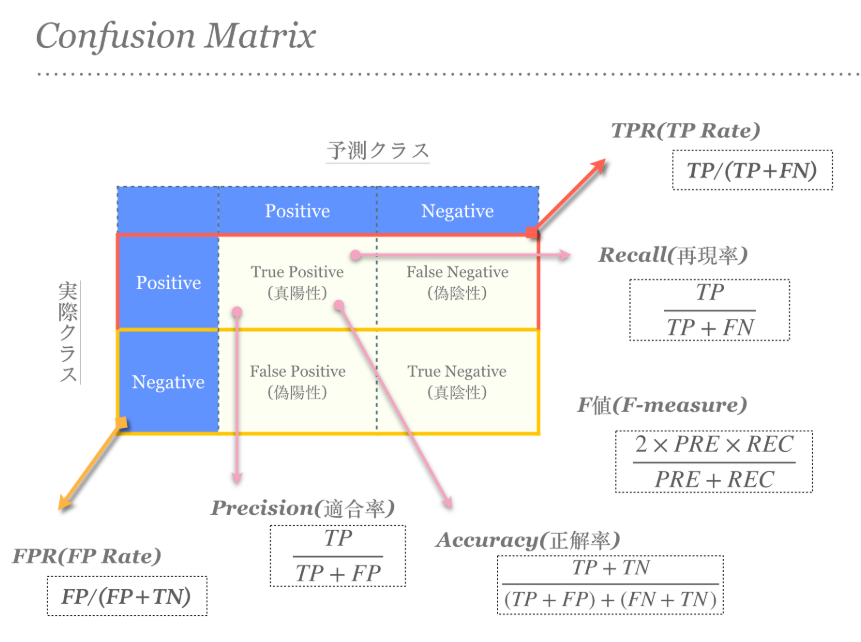
この混同行列の概念図をより理解できるように、pythonコードをまじえて解説していきます。
本記事の内容
- 混同行列(Confusion Matrix)の仕組みについて
- 混同行列(Confusion Matrix)のpython実装方法/コード
僕のブログでは【完全ガイド】pythonの学習サイトをレベル別に紹介!【基礎から機械学習・人工知能までのロードマップ】という記事も公開しています。より高みを目指したい人は参考にしてみてください。
pythonの学習ロードマップへpythonを使って「混同行列」を実装する方法を解説

必要ライブラリのインポート
まず最初に、必要ライブラリをインポートしておきましょう。
コードは下記の通りですが、ライブラリの内容を簡単に補足しておきます。
from sklearn.datasets import load_breast_cancer
Breast Cancer Wisconsinを使用するために呼び出します。これは乳がんの悪性腫瘍細胞と良性腫瘍細胞に関する569のサンプルデータと30個の特徴量が含まれているデータです。
その他
データフレームを扱うためにpandasを、混同行列を図示するためにpyplotをインポートします。numpyは今回は使用しませんが、僕の癖でインポートしています。

from sklearn.linear_model import LogisticRegression
今回の予測タスクは「良性腫瘍」か「悪性腫瘍」かを予測する二値分類タスクのため、オーソドックスにロジスティック回帰モデルを使用します。
from sklearn.preprocessing import StandardScaler
入力データを標準化するために使用
from sklearn.decomposition import PCA
特徴量が30次元となっているため、次元削減方法としてPCA(主成分分析)を用いる。
from sklearn.pipeline import Pipeline
標準化や次元圧縮を組み合わせて使うためにパイプラインをインポートする。

from sklearn.model_selection import train_test_split
ホールドアウト法によりデータを訓練データと検証データに分割する。

from sklearn.metrics import confusion_matrix
混同行列を使用するためのライブラリ。モデルからの予測値と正解ラベルを与えることで、2×2のマトリックスをarray形式で出力可能。
from sklearn.metrics import accuracy_score
正解率(Accuracy)の評価指標として使用
from sklearn.metrics import precision_score,recall_score,f1_score
適合率(Precision)、再現率(Recall)、F値(F-measure)の評価指標として使用
データセットの準備と確認
ライブラリのインポートが完了したので、データセットの準備と確認をしていきましょう。下記コーディングで入力データと正解データ(教師データ)のセッティングが可能となります。
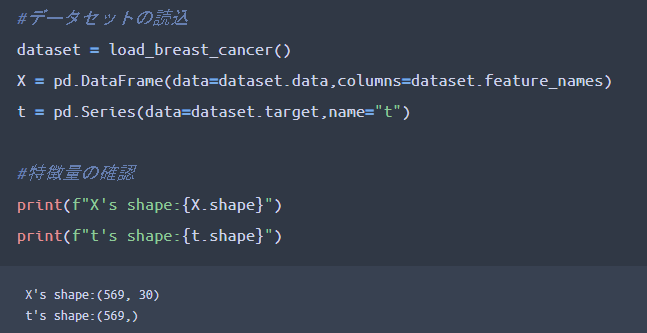
shapeの結果より、サンプルデータ数は569個、特徴量が30個あることが確認出来ます。

データセットの内容を確認してみると、上図のようになっていることがわかります。
モデリングフェーズ
データセットのセッティングが完了したので、実際にモデルを構築していきます。
その前に、ホールドアウト法を用いて、訓練データと検証データに分割していきましょう。
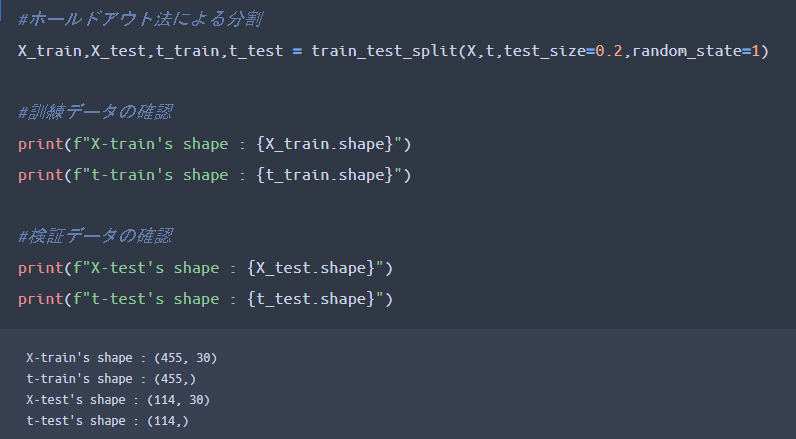
・訓練データと検証データを分割する割合は「20%」としています。
・検証用データが「114個」あるので、混同行列で114個を4象限に分類していくことになります。
訓練データと検証データへの分割が完了したので、モデリングフェーズに移ります。
最初にインポートしたパイプラインを用いて、「標準化」「PCAによる次元削減」「ロジスティック回帰によるモデル構築」を実現していきます。
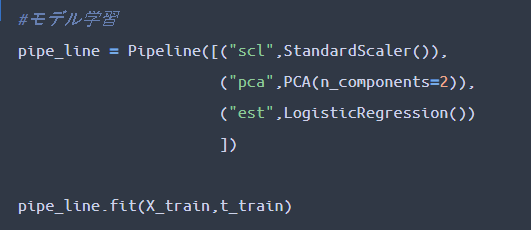
・PCAのハイパーパラメータを設定し、次元数を30個から2個までに次元削減します。
・fitメソッドを用いることで、実際に学習を開始します。
混同行列(Consufion Matrix)の作成
実際にモデルが構築出来たので、未知データ(検証データ)に対する予測結果を出しておきましょう。
最終的に「混同行列による評価指標」を用いていきますが、その前に混同行列をヒートマップで図示出来るようにしていきます。そのために、「confusion_matrix関数」を用いることで、混同行列の結果をarray形式で算出しておきます。
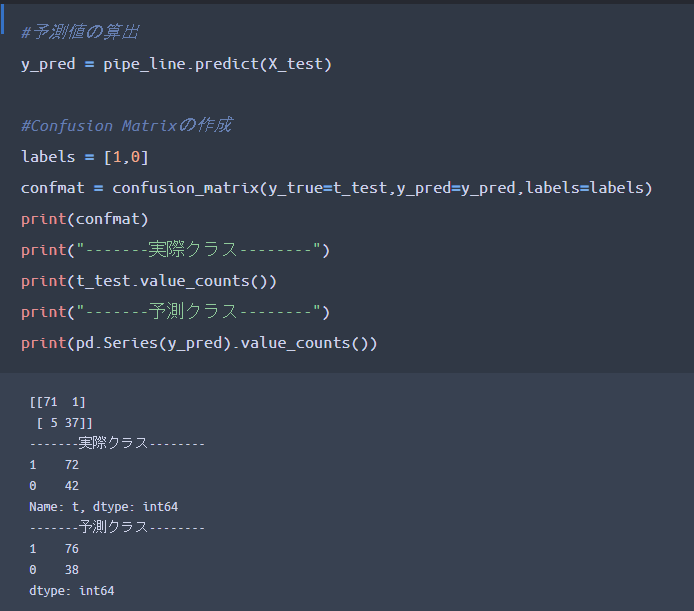
・y_pred:構築モデルに未知データ(検証データ)を予測させた結果
・confmat:混同行列の結果をconfusion_matrix関数を用いて算出
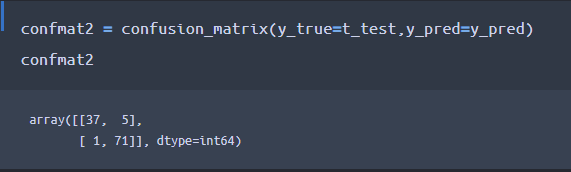
引数「labels」を指定しない場合、クラス「0」「1」の順番でソートされてしまうため、上記で意図的に引数「labels」を指定しています。下記コーディングによって、ヒートマップを用いた「混同行列」を可視化出来ます。
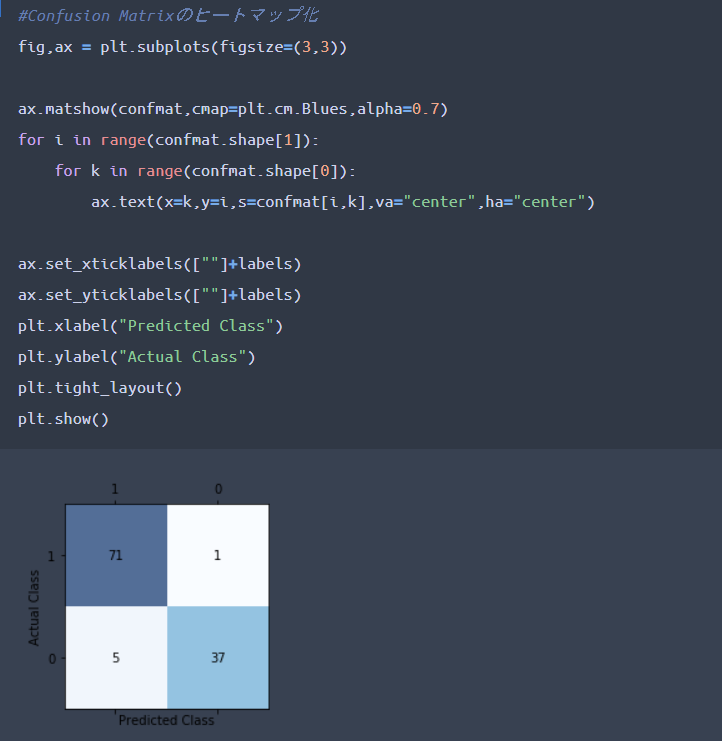
冒頭で紹介した図と比較しても、混同行列っぽくなっていることがわかるかと思います。
スコアリングフェーズ
では最後に、評価指標を用いたコーディングを見ていきましょう。
使いたい評価指標に「正解ラベル」「予測値」をインプットすれば自動的に算出してくれるので難しくありませんね。
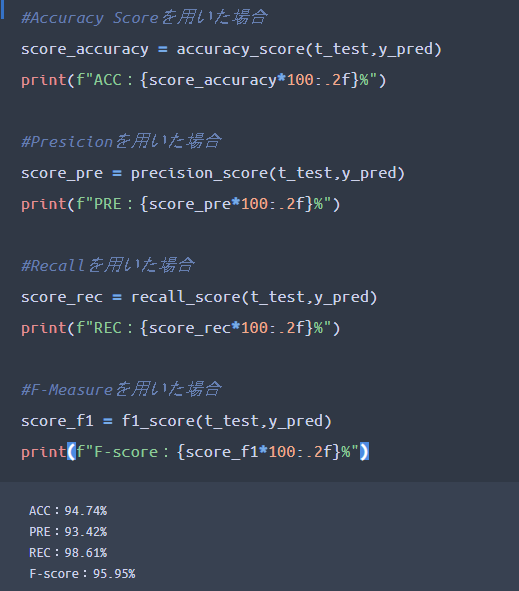
指標ごとに使うべき関数をまとめておきます。
- 正解率(Accuracy):accuracy_score関数を使う
- 適合率(Precision):precision_score関数を使う
- 再現率(Recall):recall_score関数を使う
- F値(F-measure):f1_score関数を使う
こんな感じですね。
まとめ:混同行列は概念図とpythonコードであわせて理解すべし!そうすれば混乱しにくくなる

以上が「混同行列」を用いたコーディングの紹介でした。
ライブラリに使える指標が格納されているので、必要に応じて使えるようにしておきましょう。
冒頭でも紹介しましたが、pythonの学習方法を【完全ガイド】pythonの学習サイトをレベル別に紹介!【基礎から機械学習・人工知能までのロードマップ】でまとめています。良ければあわせて読んでみてください。
【完全ガイド】pythonの学習サイトをレベル別に紹介!【基礎から機械学習・人工知能までのロードマップ】
pythonを極めたいすべての人に贈る学習ロードマップ。おすすめの学習サイトをレベル別に紹介しているので、pythonのレベルをあげていきたいと考えるすべての人に読んで欲しい記事です。これさえ読めば、自分に合っている学習方法やこれから目指すべき方向性がわかります。pythonライフ、楽しんでいきましょう。
ステキなpythonライフを。