【Python Coding】One-hot Encoding


こんにちは、TAKです。
前回記事「カテゴリ変数を数値化する必要性」の中でOne-hotエンコーディング処理を紹介したので、今回は実際にpythonを用いて「One-hotエンコーディング」を実装する方法を紹介していきたいと思います。
python codingなので、いつものようにJupyter Notebookベースでコードを紹介していきます。
必要に応じて、みなさんもローカル環境で実装トライしてみてくださいね。
One-hot エンコーディング処理
必要ライブラリのインポート
今回はpandasだけあればOKなので、上記のようにpandasをインポートしておいてください。
pandasの搭載機能でカテゴリ変数を数値化するOne-hotエンコーディング処理が実現出来ます。
データの準備
今回は「欠損値がない」場合と「欠損値がある」場合の2パターンを見ていきます。
具体的には、下記イメージのような簡単なデータを用意した上で、One-hotエンコーディングを施していきます。
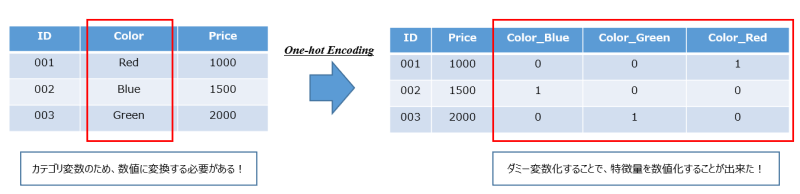

※ID 004が追加され、Color変数が欠損(N/A)となっているケースを想定します。
データの作成
では実際にpandasを用いて先ほどのデータを作成しましょう。
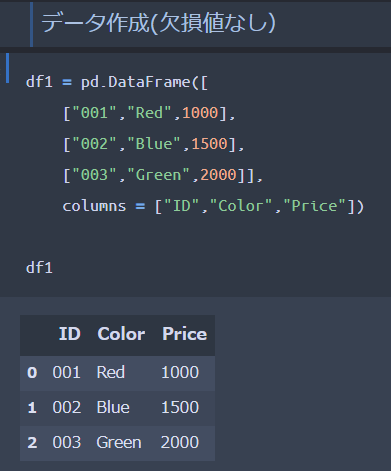
● pandasのDataFrameで新しくデータを作成出来ます

● 欠損値を作る場合は「None」をデータにいれてあげればOKです
One-hotエンコーディング処理①(欠損なし)
欠損値がない具体例①のデータに対してOne-hotエンコーディング処理を施します。
今回のメイン処理となりますが、pandasのget_dummiesを使えば自動でカテゴリ変数の数値化が可能です。
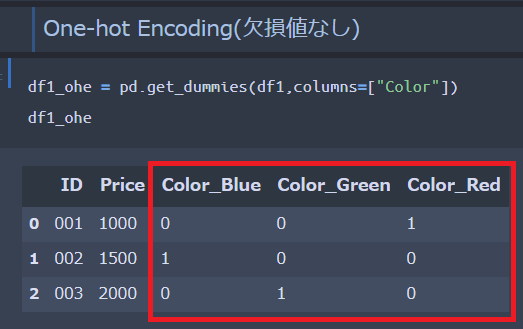
● get_dummiesの引数には、対象とするデータとカテゴリ変数の列を指定する必要あり
One-hotエンコーディング処理②(欠損あり)
次に、欠損値がある具体例②のデータに対してOne-hotエンコーディング処理を施します。
pandasのget_dummiesを用いる点は先ほどと同様ですが、引数にdummy_naを指定する点がポイントとなります。
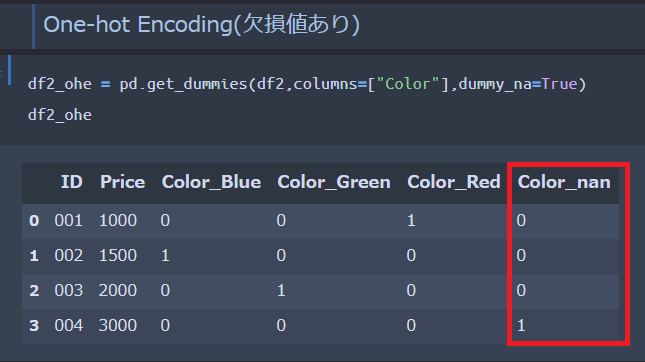
指定したカテゴリ変数の列に欠損値(N/A)が含まれている場合、dummy_naをTrueとすることで、上図赤枠のように欠損を表す列が追加されることとなります。
● get_dummiesの引数には、対象とするデータとカテゴリ変数の列を指定する必要あり
● カテゴリ変数に欠損値がある場合、引数「dummy_na」をTrueとすればOK
まとめ
いかがだったでしょうか?
以上がカテゴリ変数を数値化するOne-hotエンコーディングの処理となります。
欠損値がない場合と欠損値がある場合のように、データの内容に応じた処理を出来るようにすることが大切です。基本的な内容ではありますが、理解してしまえば応用がかなり効く手法なので、正確な「前処理」をすることでデータ分析力を向上させてみてください。
では今回はこのへんで。