【Python Coding】pandasの「rolling」で統計量を算出する方法


こんにちは、TAKです。
今回は、pythonのpandasで使える「rolling」という方法を紹介していきたいと思います。
一般的には、「移動平均」を求めたい場合や、時系列データ分析をする場合に使える方法となります。
今回の記事では前半部分で使い方の概要を紹介し、後半部分で簡単な具体例をシンプルに紹介していきます。
【こんな人に読んで欲しい記事です】
● pandasの「rolling」の使い方を知りたい方
● pandasを使ったデータ分析の幅を広げたいと考えている方
必要ライブラリのインポート
今回はデータフレームをゼロから作るのでpandasとnumpyをインポートしておきます。
後半では別途「random」「matplotlib」などを使いますが、基本的な使い方を紹介する上では不要なので、ここでは2つだけをインポートしています。
利用データの作成
rollingを使った時のイメージが湧きやすいように、以下のような10行2列のシンプルなデータを作ります。
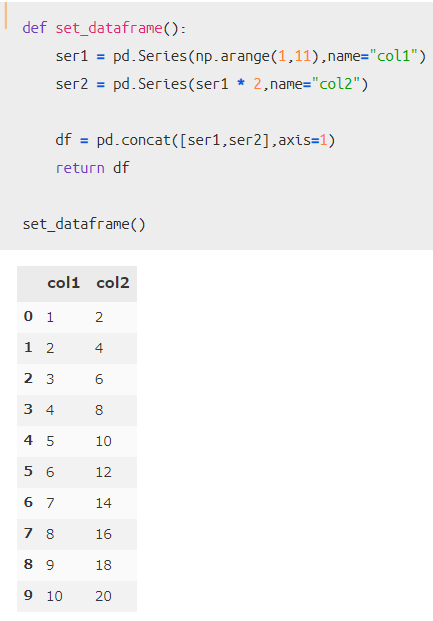
このデータフレームを使って、「rolling」の使い方と効果を見ていきましょう。
rollingとは何か?
そもそも「rolling」とは何でしょうか?
言葉で説明するのが難しいのですが、一般的にはpandasのrollingを用いることでデータフレームやシリーズに「窓関数」を適用させることが可能になる方法と言われます。
と言っても難しくてよくわかりませんよね。
直感的な使い方の説明としては、「一定の枠(window)を指定して、その枠内のデータ統計量を求める」ようなイメージを僕は持っています。例えば、枠(window)が「3つ」と設定されていて、値が「10,20,30」の場合、この3つのデータ平均を「20」と求めたり、合計「60」と求めることが出来るといったところです。
実際のコードを見てイメージを膨らませていきましょう。
rollingの使い方①|合計を算出
先ほどの例でいう「枠(window)」を「1,3,5,10」とした場合で、統計量として「合計」を求めたい場合を想定して、準備したデータにrollingを適用していきます。
rollingの基本的な使い方は`df[column].rolling().sum()`となります。
「rolling」のカッコ内で枠(window)を設定するようなイメージです。

上記コード結果の列「col1」と列「window_tx」を比べてみてください。
列「window_t10」を見てみると、最後の値だけ「55」になっていてそれ以外は欠損値となっていますね。
これは、枠(window)を「10」としているので、「10個分」のデータが集まった時の「合計」を表示しているということです。同様に考えれば、「t1」「t3」「t5」の結果も理解できるかと思います。
rollingの使い方②|平均を算出
今度は、「合計」の代わりに「平均」を使ってみましょう。
「枠(window)」を「1,3,5,10」とした場合で、統計量として「平均」を求めたい場合を想定したコードが以下となります。コードの基本的な使い方は`df[column].rolling().mean()`となります。

列「window_t10」を見てみると、最後の値だけ「5.5」になっていてそれ以外は欠損値となっていますね。
これは、先ほどの合計と比べればわかりますが、10個分の平均を取って「5.5」になっています。
いずれの場合も、枠(window)を「N」と設定した場合、データ数が「N」となった時に枠内に含まれるデータ統計量(合計や平均など)を算出していると考えれば、少しは理解しやすいかもしれません。
rollingを使った具体例
続いて、rollingを用いた簡単な具体例を紹介していきます。
時系列データを想定した方がイメージしやすいので、2020年1月から2020年3月までの売上データを作っていきます。
売上は「1,000」を基準としつつ、ランダムで変動(※)するように設定しています。
(※:最低10%(100)・最高200%(2,000))
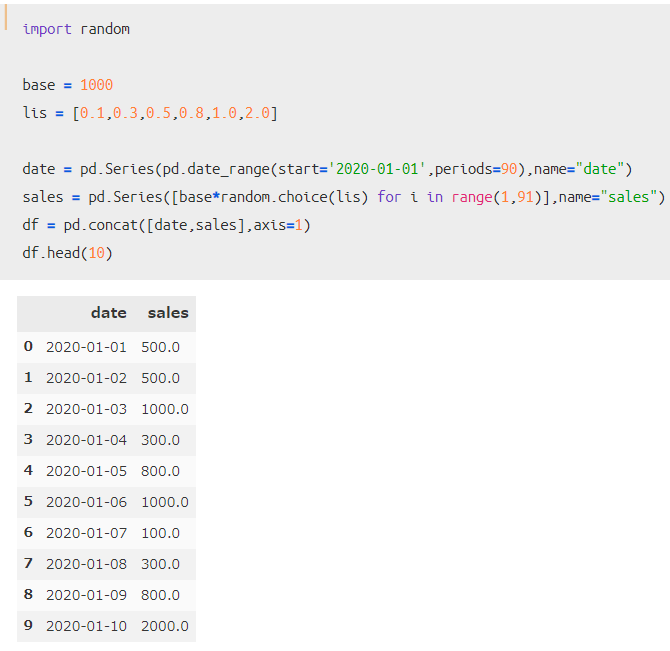
このシンプルな売上データを用いて、「7日」ごとの売上平均を算出してみます。
通常の一週間ごとの売上平均とは異なり、データが7日分溜まった後は、毎日その日までの売上平均を出している点に注意してください。
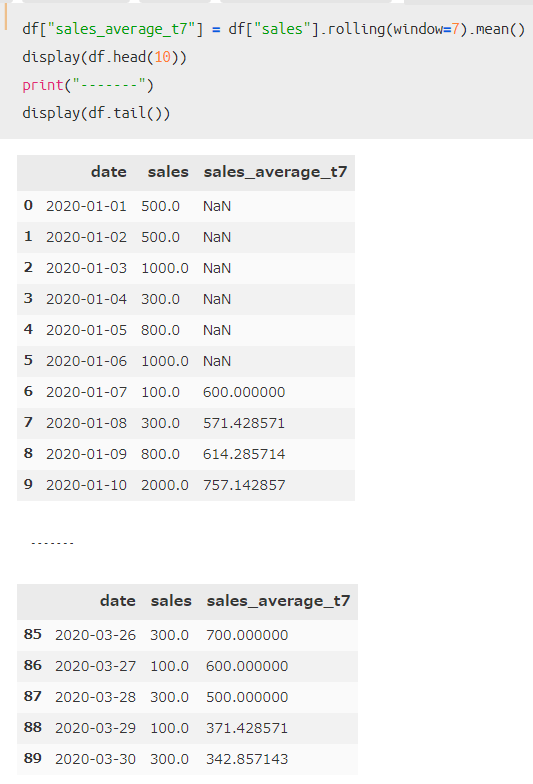
上記のように、1月1日から6日までの6日間はデータが不足していたので欠損値となっていますが、それ以降は毎日売上の平均が算出されていることがわかります。
(ちなみに、2020年2月は閏年だったことを忘れて日付設定していたので、最後が3月30日となっています。)
最後に、平均したデータを用いて可視化してみます。
今回はランダムで上下するように作っているデータなので特に意味は持ちませんが、都度平均を求めることに意義があるケース(例:株価の移動平均やコロナ感染者数の推移など)では使える方法かと思います。
さいごに
今回は、pythonのpandas機能「rolling」について紹介してきました。
なかなか使いどころが難しいと思われたかもしれませんが、知っておくといざという時に使えるので、頭の片隅にでも入れておいてください。
では今回はこのへんで。